
Overview
Kubernetes v1.34로 업그레이드한 후, kube-apiserver 로그에 아래와 같은 Warning이 30초마다 반복적으로 출력되는 현상이 보고되고 있다.
W0407 09:18:02.032615 grpc: addrConn.createTransport failed to connect to
{Addr: "10.10.10.17:2379"} Err: connection error: desc = "transport: Error while
dialing: dial tcp 10.10.10.17:2379: operation was canceled"- 이 로그만 보면 etcd 연결이 끊긴 것처럼 보이지만, 실제로는 클러스터 동작에 전혀 영향이 없는 무해한 Warning이다.
- 이번 포스팅에서는 이 Warning이 왜 발생하는지, v1.33에서는 왜 안 나왔는지, 그리고 언제 수정될 예정인지를 정리해본다.
https://github.com/kubernetes/kubernetes/issues/134080
kube-apiserver log spammed with "failed to connect to etcd" · Issue #134080 · kubernetes/kubernetes
What happened? Running 1.34.1 with talos 1.11.0 (etcd 3.6.4). It doesn't seem to be related to talos. All kube-apiserver logs are spammed every 15sec with grpc: addrConn.createTransport failed to c...
github.com
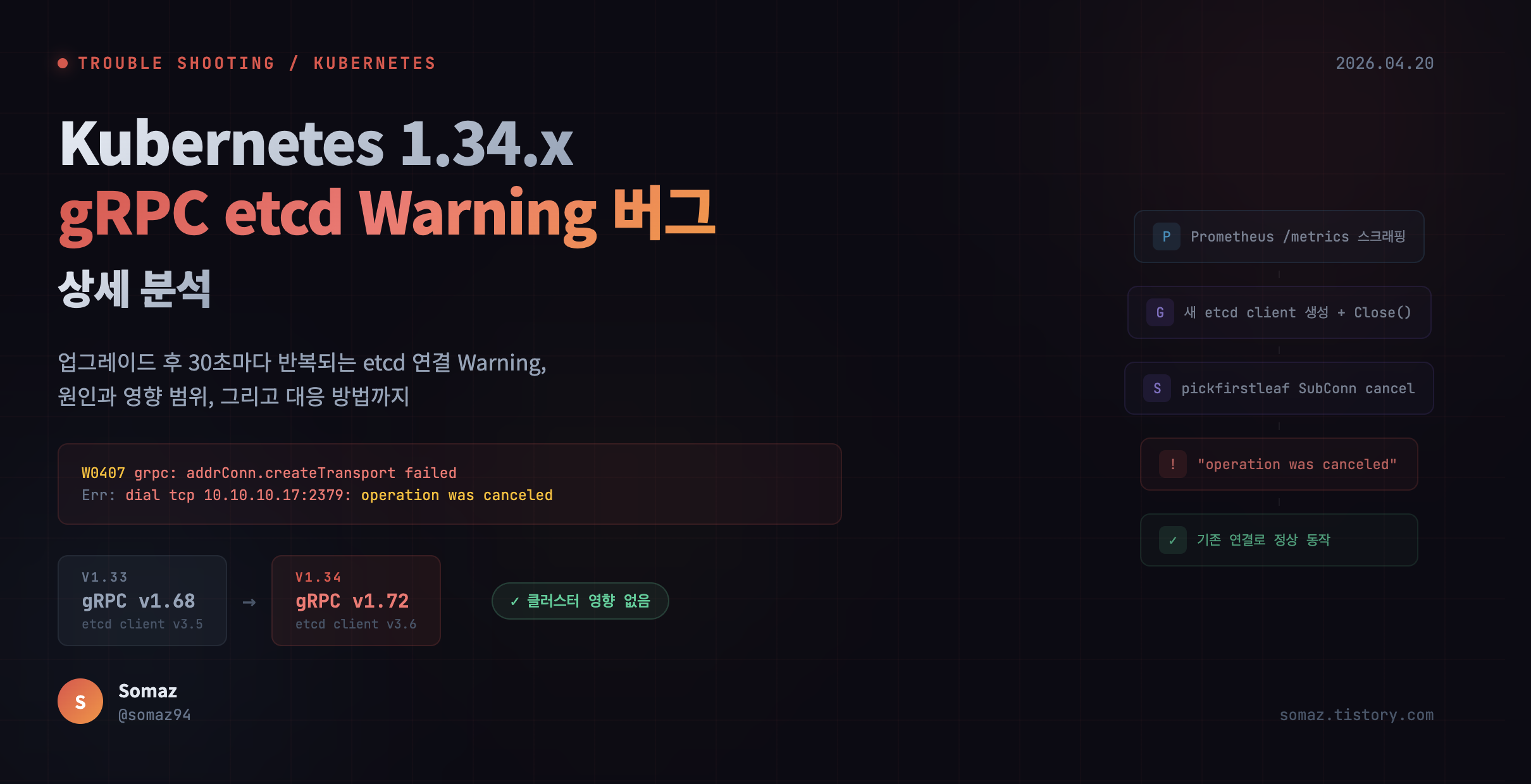
핵심 의존성 변경
K8s v1.34에서는 etcd와 gRPC 관련 핵심 의존성이 메이저 업그레이드되었다.
| 구분 | v1.33 | v1.34 |
| etcd client | v3.5.21 | v3.6.4 |
| gRPC | v1.68.1 | v1.72.1 |
단순한 패치 업데이트가 아니라 메이저 버전 변경이기 때문에, 내부 동작 방식이 크게 바뀌었다.
용어 설명
본문에 들어가기 전에 자주 등장하는 용어를 간단히 정리한다.
gRPC — Google이 만든 고성능 RPC(Remote Procedure Call) 프레임워크. Kubernetes에서 kube-apiserver와 etcd가 통신할 때 사용하는 프로토콜이다.
balancer — gRPC 내부에서 여러 서버(endpoint)에 요청을 분배하는 로직. 어떤 서버에 연결할지, 연결이 끊기면 어떻게 재시도할지를 결정한다.
SubConn — gRPC에서 하나의 서버 주소에 대한 물리적 연결 단위. balancer가 SubConn을 생성하고 관리한다.
TLS handshake — 암호화된 통신을 시작하기 전에 클라이언트와 서버가 인증서를 교환하고 암호화 방식을 합의하는 과정. etcd는 기본적으로 TLS를 사용하므로, 새 연결마다 이 과정이 필요하다.
pickfirstleaf — gRPC v1.72에서 새로 도입된 balancer 구현체. 이전의 `round_robin balancer` 를 대체한다.
monitorCollector — kube-apiserver 내부에서 etcd 스토리지 크기(`apiserver_storage_size_bytes`) 메트릭을 수집하는 컴포넌트.
원인 (Root Cause)
kube-apiserver의 `/metrics` 엔드포인트에는 `apiserver_storage_size_bytes` 메트릭을 수집하는 `monitorCollector` 가 있다.
이 컴포넌트는 메트릭을 수집할 때마다 다음과 같은 흐름을 거친다.
Prometheus가 /metrics 스크래핑 요청
→ monitorCollector.CollectWithStability() 호출
→ 새 etcd 클라이언트 생성
→ client.Status() 호출 (gRPC 연결 2개 생성)
→ 즉시 client.Close()
핵심은 매 스크래핑마다 etcd 클라이언트를 새로 만들고 바로 닫는다는 것이다.
이 패턴 자체는 v1.33에도 동일하게 존재했다. 하지만 v1.33에서는 문제가 없었다.
왜 v1.34에서만 문제인가
gRPC 내부의 balancer 구현이 완전히 바뀌었기 때문이다.
v1.33 (gRPC v1.68)
round_robin balancer
└── base.NewBalancerBuilder 사용
└── Close()가 no-op (아무것도 안 함)
└── 연결 정리 중 Warning이 발생하지 않음- `round_robin balancer` 의 `Close()` 메서드가 사실상 아무 작업도 하지 않았기 때문에, etcd 클라이언트를 만들자마자 닫아도 깔끔하게 종료되었다.
v1.34 (gRPC v1.72)
round_robin balancer (재작성됨)
└── endpointsharding + pickfirstleaf 사용
└── Close()가 SubConn 생명주기를 적극 관리
└── 아직 진행 중인 TLS handshake가 cancel됨
└── "operation was canceled" Warning 발생
새 구현에서는 `Close()` 가 모든 `SubConn` 의 상태를 추적하고 정리한다.
문제는 `Close()` 가 호출되는 시점에 아직 TLS handshake가 진행 중인 `SubConn` 이 있을 수 있다는 것이다. 이때 진행 중인 연결이 강제로 cancel되면서 Warning이 출력된다.
추가로 etcd client v3.6에서 resolver 업데이트 방식이 Addresses → Endpoints로 변경되면서, 새로운 gRPC 코드 경로가 활성화된 것도 원인 중 하나이다.
전체 흐름 정리
Prometheus --30초마다--> kube-apiserver /metrics 스크래핑
│
▼
새 etcd client 생성
│
▼
gRPC가 SubConn 열기 시작 (TLS handshake 진행 중...)
│
▼
즉시 Close() 호출
│
▼
gRPC pickfirstleaf가 아직 연결 중인 SubConn을 cancel
│
▼
"operation was canceled" Warning 출력
│
▼
실제 메트릭 수집은 기존 연결로 정상 동작- 30초마다 Warning이 나오는 이유는 Prometheus의 기본 스크래핑 간격이 30초이기 때문이다.
- 스크래핑할 때마다 새 etcd 클라이언트를 만들고 닫으면서 매번 같은 Warning이 발생하는 것이다.
영향 범위
| 항목 | 영향 |
| 클러스터 동작 | 전혀 영향 없음. 기존 ESTABLISHED 연결은 정상 동작 |
| etcd 데이터 | 영향 없음. 읽기/쓰기 정상 |
| 로그 | 30초마다 Warning 1줄 출력 (스크래핑 간격과 동일) |
| 알림 | KubeAPIErrorBudgetBurn 알림이 발생할 수 있음 |
| 성능 | 영향 없음 |
실제로 확인해보면 etcd는 정상 동작 중이다.
# etcd 상태 확인
sudo systemctl status etcd
# Active: active (running) ✅
# etcd 포트 리스닝 확인
sudo ss -tlnp | grep 2379
# LISTEN 0 4096 10.10.10.17:2379 ✅
대응 방법
지금 당장은?
무시해도 된다. 클러스터 동작에 전혀 영향이 없는 cosmetic한 Warning이다.
다만 모니터링 알림이 거슬린다면, `KubeAPIErrorBudgetBurn` 알림 규칙에서 이 패턴을 제외하거나 severity를 낮추는 것을 고려할 수 있다.
근본 수정은?
Kubernetes 공식 이슈 kubernetes/kubernetes#138075에서 수정이 진행 중이다.
수정 방향은 `/metrics` 스크래핑 시 etcd 클라이언트를 매번 새로 만들지 않고 기존 연결을 재사용하도록 변경하는 것이다. 이렇게 하면 매번 gRPC 연결을 열고 닫는 과정이 사라지므로 Warning도 발생하지 않는다.
다음 패치 릴리즈(v1.34.4 이후 또는 v1.35.x)에서 수정이 포함될 것으로 예상된다.
비슷한 상황에서의 판단 기준
업그레이드 후 etcd 관련 Warning이 보일 때, 실제 문제인지 아닌지 판단하는 기준을 정리한다.
무해한 경우 (이번 케이스)
- Warning이 일정 간격(30초)으로 규칙적으로 반복
- etcd가 active (running) 상태
- kubectl get nodes, kubectl get pods 등이 정상 동작
- etcd 포트(2379)가 리스닝 중
실제 문제인 경우
- Error 레벨 로그가 출력됨 (Warning이 아니라 Error)
- etcd 서비스가 죽어있거나 재시작을 반복
- kubectl 명령이 응답하지 않거나 타임아웃
- etcd 포트가 리스닝되지 않음
- Pod 생성/삭제가 안 됨
마무리: "Warning은 항상 위험 신호는 아니다"
Kubernetes를 운영하다 보면 업그레이드 후 낯선 Warning 로그를 만나는 경우가 많다. 이번 케이스처럼 내부 의존성(gRPC, etcd client)의 메이저 업그레이드로 인해 이전에는 없던 로그가 새로 나타나기도 한다.
중요한 것은 Warning 자체가 아니라 실제 영향이다.
- etcd가 정상이고, 클러스터가 정상 동작하고, 규칙적인 간격으로 나오는 Warning이라면 대부분 무해하다.
- 반면 불규칙하게 터지는 Error, 서비스 중단, 타임아웃이 동반된다면 즉시 대응이 필요하다.
이번 버그는 이미 Kubernetes 커뮤니티에서 인지하고 있으며, 다음 패치에서 수정될 예정이다. 그 전까지는 안심하고 운영하면 된다.
Reference
- kubernetes/kubernetes#138075 — etcd client reuse for metrics
- gRPC v1.72 Release Notes
- etcd client v3.6 Changelog
- Kubernetes v1.34 Release Notes
Somaz | DevOps Engineer | Kubernetes & Cloud Infrastructure Specialist
'Container Orchestration > Kubernetes' 카테고리의 다른 글
| Kubernetes 스토리지 타입 완벽 가이드: iSCSI, NFS... (0) | 2026.04.28 |
|---|---|
| Public Helm Chart Repository 구축하기 — 로컬 차트에서 ArtifactHub까지 (0) | 2026.04.24 |
| Kubernetes 클러스터 업그레이드하기 (kubespray 2026v.) (0) | 2026.04.13 |
| Kubernetes 클러스터 구축하기(kubespray 2026v.) (0) | 2026.04.08 |
| Kubernetes Probe (Liveness, Readiness, Startup) (0) | 2026.04.06 |