
Overview
이 글에서는 Google Cloud Platform(GCP) 을 활용하여 데이터 파이프라인을 자동화하는 방법을 소개한다. 수작업으로 반복되는 데이터 수집과 정제, 시각화 과정을 GCP의 다양한 서비스들을 조합하여 완전 자동화된 데이터 워크플로우로 전환하는 과정을 실습 중심으로 설명한다.
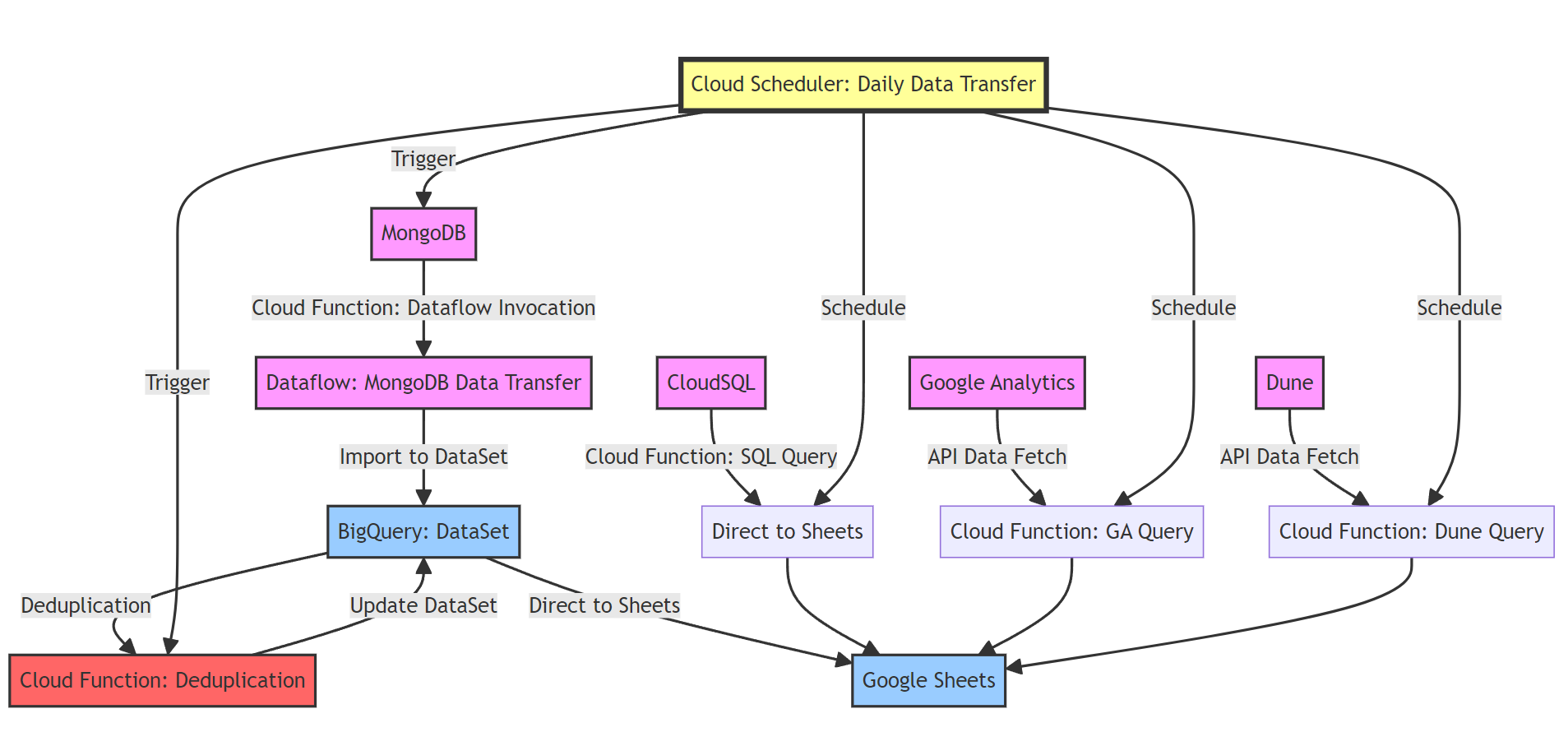
자동화 대상은 MongoDB, CloudSQL, Google Analytics(GA), Dune 등의 외부 데이터 소스이며, 이를 BigQuery에 적재하고 최종적으로 Google Sheet에 시각화 데이터를 입력하는 과정을 구성한다.
주요 기술 스택은 다음과 같다.
- BigQuery: 데이터 웨어하우스로서 중심 역할 수행
- Cloud Functions: 서버리스 컴퓨팅으로 자동화 트리거 처리
- Cloud Scheduler: 시간 기반 자동화 스케줄링
- Dataflow: MongoDB와 같은 외부 데이터의 ETL 처리
- Cloud Storage & Artifact Registry: 함수 배포용 소스코드 관리
- Terraform: 전체 인프라를 코드로 관리하는 IaC 기반 자동화
또한 실제 MongoDB → BigQuery 자동화 예제를 통해 GCP 서비스 간의 연동 방식과 쿼리 변환 로직, IAM 권한 관리, 함수 트리거 구성까지 폭넓게 다룬다.
📅 관련 글
2023.04.06 - [GCP] - GCP란? - 서비스 계정 & Project 생성 / SDK(gcloud) 설치
2023.04.06 - [GCP] - GCP IAM이란?
2023.04.12 - [GCP] - GCP - SDK(gcloud) 계정 2개 등록하기
2023.05.05 - [GCP] - GCP vs AWS 리소스 비교
2023.05.19 - [GCP] - GCP BigQuery란? & Data Warehouse
2023.09.23 - [GCP] - BigQuery와 DataFlow를 활용한 Data ETL(GCP)
2023.10.03 - [GCP] - Shared VPC를 사용하여 GKE 클러스터 생성시 IAM 설정
2023.12.18 - [GCP] - GCP를 활용한 데이터 자동화(MongoDB, CloudSQL, GA, Dune)
2024.01.20 - [GCP] - Terraform 으로 GCS 생성후 Cloud CDN 생성(GCP)
2024.03.04 - [GCP] - GCP에서 딥러닝을 위한 GPU VM 서버 만들기(GCP)
2024.04.24 - [Migration] - AWS에서 GCP로 마이그레이션하는 방법 및 고려사항
데이터 자동화
Daily 업무는 `오늘 날짜 기준으로 어제의 데이터`를 가져와서 구글시트에 입력한다.
따라서 Daily 업무의 모든 함수는 `이번달을 기준으로 지난달 마지막날 데이터 ~ 오늘까지의 데이터`를 조회한다.
Monthly 업무는 `이번달 기준으로 지난달의 데이터`를 가져와서 구글시트에 입력한다.
따라서 Monthly 업무의 모든 함수는 `이번달을 기준으로 지난달 데이터`를 조회한다.
GCP 서비스들을 사용하여 데이터 업무를 자동화한다.
- BigQuery
- Dataflow
- Cloud Functions
- Cloud Scheduler
- Cloud Storage
- Artifact Registry
DB → BigQuery
참고할 수 있는 코드는 아래의 링크에 있다.
MongoDB to BigQuery
- 서비스 계정을 생성하고 BigQuery 데이터셋을 설정
- MongoDB에서 BigQuery로 데이터를 변환하기 위해 Cloud Function을 준비하고 배포
- Cloud Scheduler를 사용하여 이 Cloud Function을 정기적으로 트리거
- Dataflow 작업을 통해 MongoDB 데이터를 BigQuery로 로드
- BigQuery에서 중복 데이터를 제거하기 위한 별도의 Cloud Function을 준비하고 배포
- 다른 Cloud Scheduler 작업을 사용하여 이 중복 제거 Cloud Function을 정기적으로 트리거

CloudSQL to BigQuery
CloudSQL은 GCP의 서비스이기 때문에 Connection을 제공해준다.

Query 변경
- MongoDB Query → BigQuery
- CloudSQL Query → BigQuery
Query Example
아래와 같이 Query를 전부 변경해준다.
- MongoDB Query
db = db.getSiblingDB("production");
db.getCollection("mongologs").aggregate([
{
$match: {
$or: [
{
time: {
$gte: ISODate(new Date(Date.UTC(new Date().getFullYear(), new Date().getMonth(), 1)).toISOString()),
$lt: ISODate(new Date(Date.UTC(new Date().getFullYear(), new Date().getMonth() + 1, 1)).toISOString())
}
},
{
time: {
$gte: ISODate(new Date(Date.UTC(new Date().getFullYear(), new Date().getMonth() - 1, new Date(new Date().getFullYear(), new Date().getMonth(), 0).getDate())).toISOString()),
$lt: ISODate(new Date(Date.UTC(new Date().getFullYear(), new Date().getMonth(), 1)).toISOString())
}
}
],
reason: "/user/create",
collectionName: { $in: ["create_user_detail"] }
}
},
{
$group: {
"_id": {
"$dateToString": {
"format": "%Y-%m-%d",
"date": "$time"
}
},
count: { $sum: 1 }
}
},
{
$sort: { _id: 1 }
}
]);
- BigQuery
SELECT
FORMAT_DATE("%Y-%m-%d", PARSE_TIMESTAMP('%a %b %d %H:%M:%S UTC %Y', time)) AS date,
COUNT(*) as count
FROM
`mgmt-2023.mongodb_dataset.production-mongodb-internal-table`
WHERE
reason = '/user/create'
AND collectionName IN UNNEST(["create_user_detail"])
AND PARSE_TIMESTAMP('%a %b %d %H:%M:%S UTC %Y', time) >= TIMESTAMP_TRUNC(CURRENT_TIMESTAMP(), MONTH)
GROUP BY
date
ORDER BY
date;
기타 설정
Dune API Key
Dune에 있는 쿼리들을 자동화하기 위해서는 API Key가 필요하다.
API Key 생성 후 확인
Google Sheet 권한 설정
자동화할 모든 Google Sheet에 사용하는 Service Account 권한설정을 해야한다.
원하는 Google Sheet에 가서 `파일 - 공유` 에 가서 권한설정을 해주면 된다.
주의! Cloud Functions와 Cloud Scheduler는 자신의 프로젝트 Service Account를 사용해야 한다.
다른 프로젝트의 Service Account를 사용해서 생성할 수 없다.
Example Code
예시 코드를 작성해보도록 한다. 더 많은 코드를 확인하고 싶으면 Reference에 있는 Github Repo로 가서 확인하면 된다.
`mongodb-bigquery-workflow.tf`
## Service Account ##
module "service_accounts_bigquery" {
source = "../../modules/service_accounts"
project_id = var.project
names = ["bigquery"]
display_name = "bigquery"
description = "bigquery admin"
}
## Biguery MongoDB Dataset ##
resource "google_bigquery_dataset" "mongodb_dataset" {
dataset_id = "mongodb_dataset"
friendly_name = "mongodb_dataset"
description = "This is a Mongodb dataset"
location = var.region
labels = local.default_labels
access {
role = "OWNER"
user_by_email = module.service_accounts_bigquery.email
}
access {
role = "OWNER"
user_by_email = "terraform@mgmt-2023.iam.gserviceaccount.com"
}
}
## cloudfunction source Bucket
resource "google_storage_bucket" "cloud_function_storage" {
name = "mongodb-bigquery-sheet-cloud-function-storage"
location = var.region
labels = local.default_labels
uniform_bucket_level_access = true
force_destroy = true
}
## mongodb -> bigquery table workflow
resource "null_resource" "mongodb_bigquery_zip_cloud_function" {
depends_on = [google_bigquery_dataset.mongodb_dataset, google_storage_bucket.cloud_function_storage]
provisioner "local-exec" {
command = <<EOT
cd ./mongodb-to-bigquery
zip -r mongodb-to-bigquery.zip main.py requirements.txt
EOT
}
triggers = {
main_content_hash = filesha256("./mongodb-to-bigquery/main.py")
requirements_content_hash = filesha256("./mongodb-to-bigquery/requirements.txt")
}
}
resource "google_storage_bucket_object" "mongodb_bigquery_cloudfunction_archive" {
depends_on = [null_resource.mongodb_bigquery_zip_cloud_function]
name = "source/mongodb-to-bigquery.zip"
bucket = google_storage_bucket.cloud_function_storage.name
source = "./mongodb-to-bigquery/mongodb-to-bigquery.zip"
}
## cloud_function
resource "google_cloudfunctions_function" "mongodb_bigquery_dataflow_function" {
depends_on = [null_resource.mongodb_bigquery_zip_cloud_function, google_storage_bucket_object.mongodb_bigquery_cloudfunction_archive]
name = "mongodb-to-bigquery-dataflow"
description = "Function to mongodb-to-bigquery the Dataflow job"
runtime = "python38"
service_account_email = module.service_accounts_bigquery.email
docker_registry = "ARTIFACT_REGISTRY"
timeout = 540
available_memory_mb = 512
source_archive_bucket = google_storage_bucket.cloud_function_storage.name
source_archive_object = google_storage_bucket_object.mongodb_bigquery_cloudfunction_archive.name
trigger_http = true
entry_point = "start_dataflow"
environment_variables = {
PROJECT_ID = var.project,
REGION = var.region,
SHARED_VPC = var.shared_vpc,
SUBNET_SHARE = var.subnet_share,
SERVICE_ACCOUNT_EMAIL = module.service_accounts_bigquery.email
}
}
## cloud_scheduler
resource "google_cloud_scheduler_job" "mongodb_bigquery_job" {
depends_on = [google_cloudfunctions_function.mongodb_bigquery_dataflow_function]
name = "mongodb-to-bigquery-daily-job"
region = var.region
schedule = "20 9 * * *" # Daily 09:20 AM
time_zone = "Asia/Seoul"
http_target {
http_method = "POST"
uri = google_cloudfunctions_function.mongodb_bigquery_dataflow_function.https_trigger_url
oidc_token {
service_account_email = module.service_accounts_bigquery.email
}
}
}
`main.tf`
import os
from googleapiclient.discovery import build
from oauth2client.client import GoogleCredentials
from flask import jsonify
def start_dataflow(request):
# HTTP requests are Flask Request objects, so you can use the object's methods to analyze the request data.
# If you want to receive data as a POST request, or if you want to use another method, modify this part appropriately.
# Importing Environment Variables
PROJECT_ID = os.environ.get('PROJECT_ID')
REGION = os.environ.get('REGION')
SHARED_VPC = os.environ.get('SHARED_VPC')
SUBNET_SHARE = os.environ.get('SUBNET_SHARE')
SERVICE_ACCOUNT_EMAIL = os.environ.get('SERVICE_ACCOUNT_EMAIL')
# Initialize Google Cloud SDK Authentication
credentials = GoogleCredentials.get_application_default()
# Creating API clients for Dataflow services
service = build('dataflow', 'v1b3', credentials=credentials)
databases = ["production"] # List of your MongoDB databases
responses = []
for database in databases:
# Setting Dataflow Job Parameters
# https://cloud.google.com/dataflow/docs/reference/rest/v1b3/projects.locations.flexTemplates/launch
# https://cloud.google.com/dataflow/docs/guides/templates/provided/mongodb-to-bigquery?hl=ko#api
# https://console.cloud.google.com/storage/browser/_details/dataflow-templates/latest/flex/MongoDB_to_BigQuery;tab=live_object?hl=ko
job_parameters = {
"launchParameter": {
"jobName": f"{database}-to-bigquery-job",
"parameters": {
"mongoDbUri": f"mongodb://mongo:somaz!2023@34.11.11.111:27017", # mongodb://<DB id>:<DB Password>@<DB IP>:<DB Port>
"database": database,
"collection": "mongologs",
"outputTableSpec": f"{PROJECT_ID}:mongodb_dataset.{database}-mongodb-internal-table",
"userOption": "FLATTEN"
},
"environment": {
"tempLocation": "gs://bigquery-sheet-cloud-function-storage/tmp",
"network": SHARED_VPC,
"subnetwork": f"regions/{REGION}/subnetworks/{SUBNET_SHARE}-mgmt-b",
"serviceAccountEmail": SERVICE_ACCOUNT_EMAIL
},
"containerSpecGcsPath": 'gs://dataflow-templates/latest/flex/MongoDB_to_BigQuery'
}
}
# error handling
try:
# Starting Dataflow Job
request = service.projects().locations().flexTemplates().launch(
projectId=PROJECT_ID,
location=REGION,
body=job_parameters
)
response = request.execute()
responses.append(response)
except Exception as e:
print(f"Error occurred while processing {database}: {e}")
responses.append({"database": database, "error": str(e)})
return jsonify(responses)
requirements.txt
google-api-python-client
oauth2client
Flask<3.0,>=1.0
werkzeug
마무리
이번 글을 통해 GCP의 다양한 서비스들을 조합하여 데이터 자동화 파이프라인을 구축하는 전반적인 과정을 정리해보았다.
MongoDB, CloudSQL, GA, Dune 등 여러 소스로부터 데이터를 수집하고, 이를 BigQuery로 집계 및 정제한 후, Google Sheet로 결과를 전달하는 흐름은 실무에서 매우 활용도가 높은 아키텍처다.
Terraform을 통한 IaC 적용, Cloud Function과 Scheduler의 서버리스 자동화, Dataflow를 통한 대용량 ETL 처리는 모두 실전 데이터 플랫폼 구성에서 유용하게 쓰일 수 있는 방법들이다.
반복적인 데이터 입력 작업을 자동화하고 싶은가? GCP의 강력한 기능들을 조합하면 완전한 데이터 자동화 시스템을 손쉽게 구축할 수 있다.
Reference
https://github.com/somaz94/terraform-bigquery-googlesheet
'GCP' 카테고리의 다른 글
| GCP에서 딥러닝을 위한 GPU VM 서버 만들기(GCP) (0) | 2024.03.04 |
|---|---|
| Terraform 으로 GCS 생성후 Cloud CDN 생성(GCP) (0) | 2024.01.22 |
| Shared VPC를 사용하여 GKE 클러스터 생성시 IAM 설정 (0) | 2023.10.08 |
| BigQuery와 DataFlow를 활용한 Data ETL(GCP) (0) | 2023.10.02 |
| GCP BigQuery란? & Data Warehouse (0) | 2023.05.21 |