
Overview
스터디 5주차에서는 쿠버네티스 모니터링 도구인 프로메테우스(Prometheus)와 시각화 도구인 그라파나(Grafana)에 대해 학습하고 실습해보는 시간을 가졌다.
이번 주 실습은 '24단계 실습으로 정복하는 쿠버네티스' 책을 바탕으로 구성되었으며, 스터디원 이현수님의 정리 자료를 함께 참고하였다.
주요 실습 내용은 다음과 같다.
- Prometheus 스택 설치 및 웹 접속 구성
- Grafana 설치 및 여러 공식 대시보드 추가 (13332, 1860, 3662, 15661)
- NGINX 웹서버 Helm Chart 배포 및 Exporter 기반 Prometheus 연동
- NGINX 관련 메트릭 Prometheus 및 Grafana에 연동
- Grafana에 공식 NGINX Dashboard (12708) 임포트 및 시각화 확인
- Metrics Server, kube-state-metrics, node-exporter 등의 메트릭 수집 확인
- Ingress + ALB + ACM 인증서를 통한 외부 웹 접근 구성
이번 실습을 통해 Prometheus가 어떻게 다양한 애플리케이션 메트릭을 수집하고, Grafana에서 어떻게 시각화할 수 있는지 명확히 이해할 수 있었다.

5주차 과제 내용
[과제1]
프로메테우스-스택 설치 후 ‘공식 or 여러가지 대시보드’를 추가해보시고, 관련 스샷 올려주세요
- 자세한 설명은 아래의 스터디 주요내용에 명시되어있습니다. 관련 스샷만 먼저 올립니다.


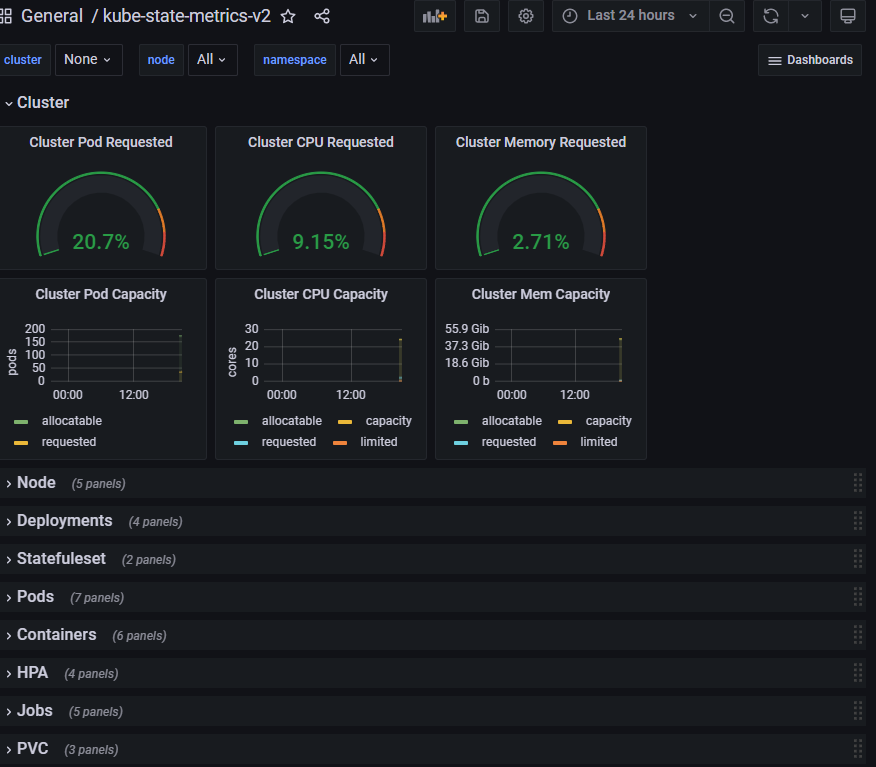



[과제2]
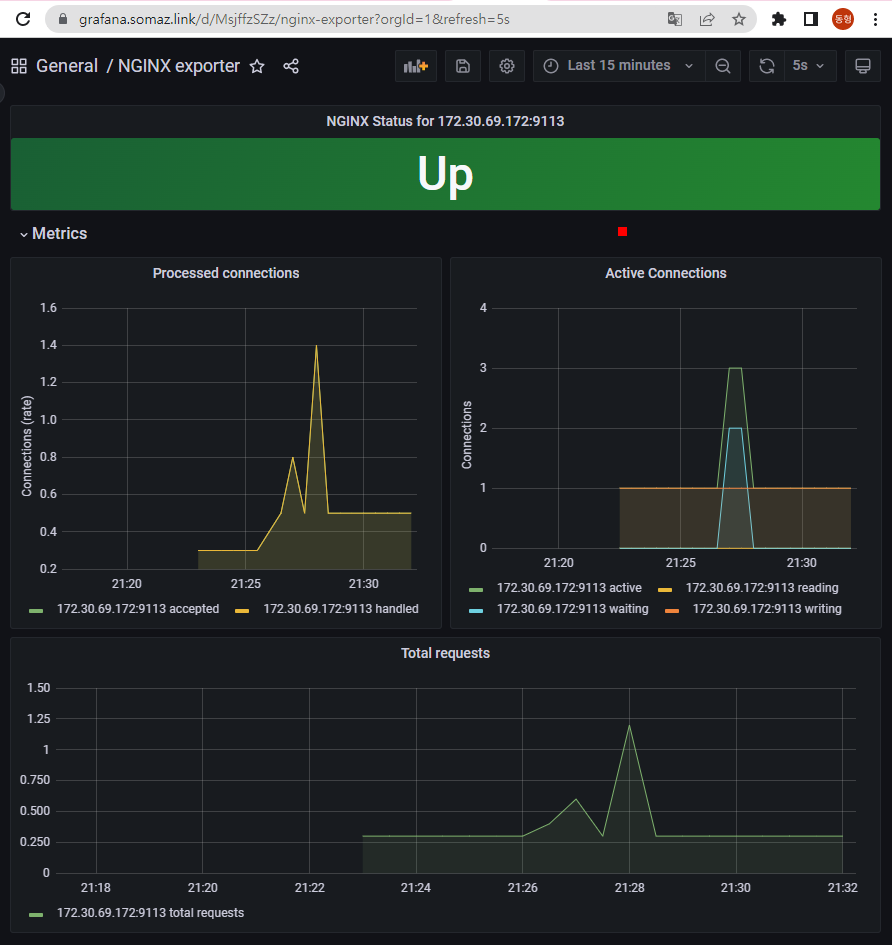
Nginx 파드를 배포 후 관련 metric 를 프로메테우스 웹에서 확인하고, 그라파나에 nginx 웹서버 대시보드를 추가 후 확인하시고, 관련 스샷 올려주세요
- 마찬가지로 자세한 설명은 아래의 스터디 주요내용에 명시되어있습니다. 관련 스샷만 먼저 올립니다.
- State → Targets 에 nginx 서비스 모니터 추가 확인

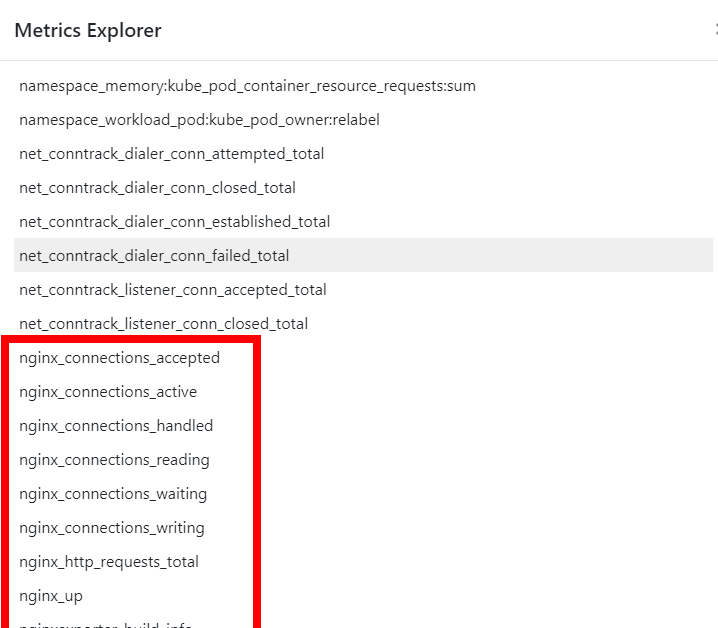
NGINX 애플리케이션 모니터링 대시보드 추가
- 그라파나에 12708 대시보드 추가
스터디 주요내용
실습 환경 배포
실습 환경
kops 인스턴스 t3.small & 노드 c5.2xlarge (vCPU 8, Memory 16GiB) 배포
이번주 실습에서 성능을 요구하는 파드를 사용한다.
- Tip. 실행하는 PC에 aws cli 설치되어 있고, aws configure 자격증명 설정 상태.
# YAML 파일 다운로드
curl -O https://s3.ap-northeast-2.amazonaws.com/cloudformation.cloudneta.net/K8S/kops-oneclick.yaml
# CloudFormation 스택 배포 : 노드 인스턴스 타입 변경 - MasterNodeInstanceType=c5d.large WorkerNodeInstanceType=c5d.large
aws cloudformation deploy --template-file kops-oneclick.yaml --stack-name mykops --parameter-overrides KeyName=somazkey SgIngressSshCidr=$(curl -s ipinfo.io/ip)/32 MyIamUserAccessKeyID=AKIA5... MyIamUserSecretAccessKey='CVNa2...' ClusterBaseName='somaz.link' S3StateStore='somaz-k8s-s3' MasterNodeInstanceType=c5.2xlarge WorkerNodeInstanceType=c5.2xlarge --region ap-northeast-2
# CloudFormation 스택 배포 완료 후 kOps EC2 IP 출력
aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text
# 마스터노드 SSH 접속
ssh -i ~/.ssh/somazkey.pem ec2-user@$(aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text)
EC2 instance profiles 설정 및 AWS LoadBalancer 배포 & ExternalDNS & Metrics-server 설치 및 배포
- 9분 정도 추가 시간 소요
# EC2 instance profiles 에 IAM Policy 추가(attach)
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --role-name masters.$KOPS_CLUSTER_NAME
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --role-name nodes.$KOPS_CLUSTER_NAME
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AllowExternalDNSUpdates --role-name masters.$KOPS_CLUSTER_NAME
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AllowExternalDNSUpdates --role-name nodes.$KOPS_CLUSTER_NAME
# kOps 클러스터 편집 : 아래 내용 추가
kops edit cluster
-----
spec:
certManager:
enabled: true
awsLoadBalancerController:
enabled: true
externalDns:
provider: external-dns
metricsServer:
enabled: true
-----
# 업데이트 적용 : 마스터 노드 롤링업데이트 필요 >> EC2인스턴스 삭제 후 재생성되므로 9분 정소 시간이 소요됨
kops update cluster --yes && echo && sleep 3 && kops rolling-update cluster --yes
Metrics-server 확인 : kubelet으로부터 수집한 리소스 메트릭을 수집 및 집계하는 클러스터 애드온 구성 요소

# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
(somaz:N/A) [root@kops-ec2 ~]# kubectl get pod -n kube-system -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-6d48674cf8-bd5dz 1/1 Running 0 2m53s
metrics-server-6d48674cf8-g29qr 1/1 Running 0 2m53s
(somaz:N/A) [root@kops-ec2 ~]# kubectl get apiservices |egrep '(AVAILABLE|metrics)'
NAME SERVICE AVAILABLE AGE
v1beta1.metrics.k8s.io kube-system/metrics-server True 3m54s
# 노드 메트릭 확인
(somaz:N/A) [root@kops-ec2 ~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
i-05f556682f22e0e6f 25m 0% 989Mi 6%
i-0949cd7beadbc375c 26m 0% 999Mi 6%
i-0dfce165f40609933 102m 1% 2175Mi 14%
# 파드 메트릭 확인
(somaz:N/A) [root@kops-ec2 ~]# kubectl top pod -A
NAMESPACE NAME CPU(cores) MEMORY(bytes)
kube-system aws-cloud-controller-manager-lpr5k 2m 21Mi
kube-system aws-load-balancer-controller-68c78954d9-rtkf8 2m 31Mi
kube-system aws-node-6swbs 3m 35Mi
kube-system aws-node-82rnq 2m 33Mi
kube-system aws-node-m9mcp 2m 33Mi
kube-system cert-manager-6b55fb8f96-m6b84 1m 21Mi
kube-system cert-manager-cainjector-5cf5bd97fc-8b5r4 1m 18Mi
kube-system cert-manager-webhook-66ccfc975d-m6tlr 1m 12Mi
kube-system coredns-6897c49dc4-86v4g 1m 14Mi
kube-system coredns-6897c49dc4-zhqbk 1m 14Mi
kube-system coredns-autoscaler-5685d4f67b-9tfzr 1m 4Mi
kube-system dns-controller-6f8cbcbb69-sxmzz 1m 13Mi
kube-system ebs-csi-controller-657d666f54-5pl9f 3m 51Mi
kube-system ebs-csi-node-964xr 1m 22Mi
kube-system ebs-csi-node-grsbq 1m 22Mi
kube-system ebs-csi-node-kwgtf 1m 21Mi
kube-system etcd-manager-events-i-0dfce165f40609933 4m 30Mi
kube-system etcd-manager-main-i-0dfce165f40609933 17m 62Mi
kube-system external-dns-844d94fdd8-mhrsk 1m 21Mi
kube-system kops-controller-kzggj 1m 17Mi
kube-system kube-apiserver-i-0dfce165f40609933 38m 385Mi
kube-system kube-controller-manager-i-0dfce165f40609933 9m 55Mi
kube-system kube-proxy-i-05f556682f22e0e6f 1m 11Mi
kube-system kube-proxy-i-0949cd7beadbc375c 1m 11Mi
kube-system kube-proxy-i-0dfce165f40609933 1m 12Mi
kube-system kube-scheduler-i-0dfce165f40609933 2m 20Mi
kube-system metrics-server-6d48674cf8-bd5dz 2m 15Mi
kube-system metrics-server-6d48674cf8-g29qr 2m 18Mi
(somaz:N/A) [root@kops-ec2 ~]# kubectl top pod -n kube-system --sort-by='cpu'
NAME CPU(cores) MEMORY(bytes)
kube-apiserver-i-0dfce165f40609933 32m 385Mi
etcd-manager-main-i-0dfce165f40609933 15m 64Mi
kube-controller-manager-i-0dfce165f40609933 7m 55Mi
etcd-manager-events-i-0dfce165f40609933 6m 30Mi
aws-node-82rnq 4m 33Mi
ebs-csi-controller-657d666f54-5pl9f 2m 51Mi
metrics-server-6d48674cf8-g29qr 2m 18Mi
aws-node-6swbs 2m 35Mi
aws-node-m9mcp 2m 33Mi
metrics-server-6d48674cf8-bd5dz 2m 15Mi
kube-scheduler-i-0dfce165f40609933 2m 20Mi
aws-cloud-controller-manager-lpr5k 2m 21Mi
cert-manager-webhook-66ccfc975d-m6tlr 1m 12Mi
kops-controller-kzggj 1m 17Mi
ebs-csi-node-grsbq 1m 22Mi
ebs-csi-node-kwgtf 1m 22Mi
dns-controller-6f8cbcbb69-sxmzz 1m 13Mi
coredns-autoscaler-5685d4f67b-9tfzr 1m 4Mi
external-dns-844d94fdd8-mhrsk 1m 21Mi
ebs-csi-node-964xr 1m 22Mi
coredns-6897c49dc4-zhqbk 1m 14Mi
coredns-6897c49dc4-86v4g 1m 14Mi
kube-proxy-i-05f556682f22e0e6f 1m 11Mi
kube-proxy-i-0949cd7beadbc375c 1m 11Mi
kube-proxy-i-0dfce165f40609933 1m 12Mi
cert-manager-cainjector-5cf5bd97fc-8b5r4 1m 18Mi
cert-manager-6b55fb8f96-m6b84 1m 21Mi
aws-load-balancer-controller-68c78954d9-rtkf8 1m 31Mi
(somaz:N/A) [root@kops-ec2 ~]# kubectl top pod -n kube-system --sort-by='memory'
NAME CPU(cores) MEMORY(bytes)
kube-apiserver-i-0dfce165f40609933 32m 385Mi
etcd-manager-main-i-0dfce165f40609933 15m 64Mi
kube-controller-manager-i-0dfce165f40609933 7m 55Mi
ebs-csi-controller-657d666f54-5pl9f 2m 51Mi
aws-node-6swbs 2m 35Mi
aws-node-82rnq 4m 33Mi
aws-node-m9mcp 2m 33Mi
aws-load-balancer-controller-68c78954d9-rtkf8 1m 31Mi
etcd-manager-events-i-0dfce165f40609933 6m 30Mi
ebs-csi-node-964xr 1m 22Mi
ebs-csi-node-grsbq 1m 22Mi
ebs-csi-node-kwgtf 1m 22Mi
external-dns-844d94fdd8-mhrsk 1m 21Mi
cert-manager-6b55fb8f96-m6b84 1m 21Mi
aws-cloud-controller-manager-lpr5k 2m 21Mi
kube-scheduler-i-0dfce165f40609933 2m 20Mi
metrics-server-6d48674cf8-g29qr 2m 18Mi
cert-manager-cainjector-5cf5bd97fc-8b5r4 1m 18Mi
kops-controller-kzggj 1m 17Mi
metrics-server-6d48674cf8-bd5dz 2m 15Mi
coredns-6897c49dc4-86v4g 1m 14Mi
coredns-6897c49dc4-zhqbk 1m 14Mi
dns-controller-6f8cbcbb69-sxmzz 1m 13Mi
cert-manager-webhook-66ccfc975d-m6tlr 1m 12Mi
kube-proxy-i-0dfce165f40609933 1m 12Mi
kube-proxy-i-0949cd7beadbc375c 1m 11Mi
kube-proxy-i-05f556682f22e0e6f 1m 11Mi
coredns-autoscaler-5685d4f67b-9tfzr 1m 4Mi
명령어 기반 쿠버네티스 모니터링 도구 k9s
- 24단계 실습으로 정복하는 쿠버네티스 책 p292 ~ 297
프로메테우스 Prometheus
소개
- Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud
제공기능
- a multi-dimensional data model with time series data(=TSDB, 시계열 데이터베이스) identified by metric name and key/value pairs
- PromQL, a flexible query language to leverage this dimensionality
- no reliance on distributed storage; single server nodes are autonomous
- time series collection happens via a pull model over HTTP ⇒ Push 와 Pull 수집 방식 장단점 - 링크
- pushing time series is supported via an intermediary gateway
- targets are discovered via service discovery or static configuration
- multiple modes of graphing and dashboarding support
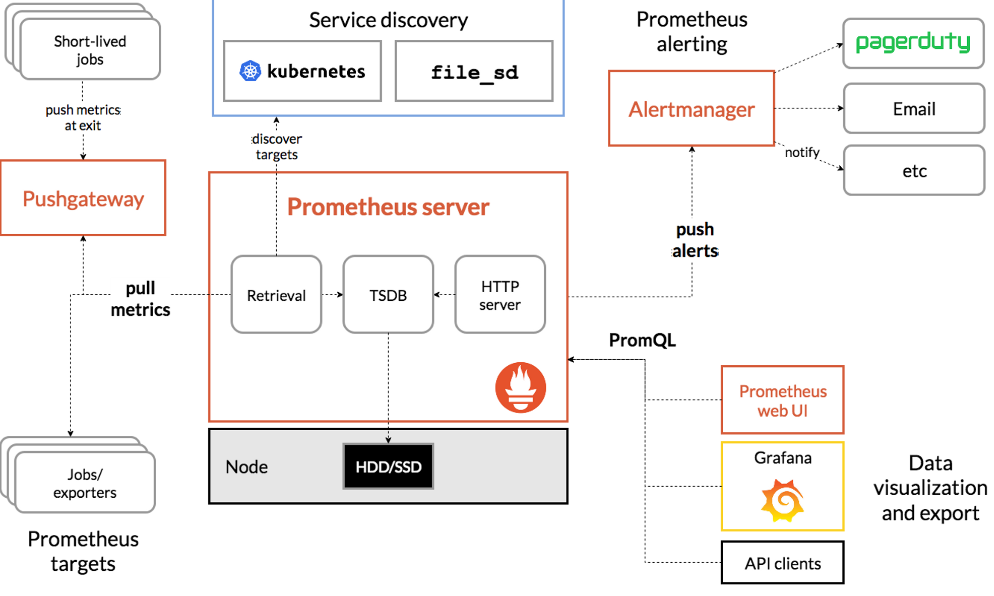
구성요소
- the main Prometheus server which scrapes and stores time series data
- client libraries for instrumenting application code
- a push gateway for supporting short-lived jobs
- special-purpose exporters for services like HAProxy, StatsD, Graphite, etc.
- an alertmanager to handle alerts
- various support tools
프로메테우스-스택 설치
- 모니터링에 필요한 여러 요소를 단일 차트(스택)으로 제공 ← 시각화(그라파나), 이벤트 메시지 정책(경고 임계값, 경고 수준) 등 - Helm
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
(somaz:N/A) [root@kops-ec2 ~]# CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
(somaz:N/A) [root@kops-ec2 ~]# echo "alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN"
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:ap-northeast-2:6118410...
# 설치
(somaz:N/A) [root@kops-ec2 ~]# helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
"prometheus-community" has been added to your repositories
# 파라미터 파일 생성
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.$KOPS_CLUSTER_NAME
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator # password
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.$KOPS_CLUSTER_NAME
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.$KOPS_CLUSTER_NAME
paths:
- /*
prometheusSpec:
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
EOT
# 변수 값 확인
(somaz:N/A) [root@kops-ec2 ~]# cat monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:ap-northeast-2:61184...
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.somaz.link
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:ap-northeast-2:61184...
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.somaz.link
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:ap-northeast-2:61184...
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.somaz.link
paths:
- /*
prometheusSpec:
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
kubectl get pod,pvc,svc,ingress -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,alertmanager -n monitoring
kubectl get servicemonitors -n monitoring
kubectl get prometheusrule -n monitoring
kubectl krew install df-pv && kubectl df-pv
(somaz:N/A) [root@kops-ec2 ~]# helm list -n monitoring
NAME NAMESPACE REVISION UPDATED
STATUS CHART APP VERSION
kube-prometheus-stack monitoring 1 2023-02-12 20:17:18.050588555 +0900 KST deployed kube-prometheus-stack-45.0.0 v0.63.0
(somaz:N/A) [root@kops-ec2 ~]# kubectl get pod,pvc,svc,ingress -n monitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-kube-prometheus-stack-alertmanager-0 2/2 Running 1 (3m24s ago) 3m29s
pod/kube-prometheus-stack-grafana-864857fd89-2l49d 3/3 Running 0
3m40s
pod/kube-prometheus-stack-kube-state-metrics-75b97d7857-bplwl 1/1 Running 0
3m40s
pod/kube-prometheus-stack-operator-58f4954646-jsb5n 1/1 Running 0
3m40s
pod/kube-prometheus-stack-prometheus-node-exporter-f5lkk 1/1 Running 0
3m40s
pod/kube-prometheus-stack-prometheus-node-exporter-smlch 1/1 Running 0
3m40s
pod/kube-prometheus-stack-prometheus-node-exporter-x95gq 1/1 Running 0
3m40s
pod/prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0
3m29s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 3m29s
service/kube-prometheus-stack-alertmanager ClusterIP 100.66.255.171 <none> 9093/TCP 3m40s
service/kube-prometheus-stack-grafana ClusterIP 100.66.78.100 <none> 80/TCP 3m40s
service/kube-prometheus-stack-kube-state-metrics ClusterIP 100.68.106.32 <none> 8080/TCP 3m40s
service/kube-prometheus-stack-operator ClusterIP 100.70.244.91 <none> 443/TCP 3m40s
service/kube-prometheus-stack-prometheus ClusterIP 100.71.254.17 <none> 9090/TCP 3m40s
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 100.67.140.140 <none> 9100/TCP 3m40s
service/prometheus-operated ClusterIP None <none> 9090/TCP 3m29s
NAME CLASS HOSTS
ADDRESS PORTS AGE
ingress.networking.k8s.io/kube-prometheus-stack-alertmanager alb alertmanager.somaz.link k8s-monitoring-74e55dbc97-980732510.ap-northeast-2.elb.amazonaws.com 80 3m40s
ingress.networking.k8s.io/kube-prometheus-stack-grafana alb grafana.somaz.link k8s-monitoring-74e55dbc97-980732510.ap-northeast-2.elb.amazonaws.com 80 3m40s
ingress.networking.k8s.io/kube-prometheus-stack-prometheus alb prometheus.somaz.link k8s-monitoring-74e55dbc97-980732510.ap-northeast-2.elb.amazonaws.com 80 3m40s(참고) 삭제 시
# helm 삭제
helm uninstall -n monitoring kube-prometheus-stack
# crd 삭제
kubectl delete crd alertmanagerconfigs.monitoring.coreos.com
kubectl delete crd alertmanagers.monitoring.coreos.com
kubectl delete crd podmonitors.monitoring.coreos.com
kubectl delete crd probes.monitoring.coreos.com
kubectl delete crd prometheuses.monitoring.coreos.com
kubectl delete crd prometheusrules.monitoring.coreos.com
kubectl delete crd servicemonitors.monitoring.coreos.com
kubectl delete crd thanosrulers.monitoring.coreos.com
프로메테우스 기본 사용 : 모니터링 그래프
- 모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출
- 이후 프로메테우스는 해당 경로에 http get 방식으로 메트릭 정보를 가져와 TSDB 형식으로 저장
(somaz:N/A) [root@kops-ec2 ~]# kubectl get node -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
i-05f556682f22e0e6f Ready node 32m v1.24.10 172.30.33.64 3.35.135.252 Ubuntu 20.04.5 LTS 5.15.0-1028-aws containerd://1.6.10
i-0949cd7beadbc375c Ready node 32m v1.24.10 172.30.72.213 13.125.84.156 Ubuntu 20.04.5 LTS 5.15.0-1028-aws containerd://1.6.10
i-0dfce165f40609933 Ready control-plane 23m v1.24.10 172.30.61.109 3.36.67.170 Ubuntu 20.04.5 LTS 5.15.0-1028-aws containerd://1.6.10
(somaz:N/A) [root@kops-ec2 ~]# kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 100.67.140.140 <none> 9100/TCP 7m56s
NAME ENDPOINTS
AGE
endpoints/kube-prometheus-stack-prometheus-node-exporter 172.30.33.64:9100,172.30.61.109:9100,172.30.72.213:9100 7m56s
# endpoint는 node의 INTERNAL-IP이다.
# 마스터노드에 lynx 설치
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME hostname
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME sudo apt install lynx -y
# 노드의 9100번의 /metrics 접속 시 다양한 메트릭 정보를 확인할수 있음 : 마스터 이외에 워커노드도 확인 가능
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME lynx -dump localhost:9100/metrics
프로메테우스 ingress 도메인으로 웹 접속
(somaz:N/A) [root@kops-ec2 ~]# kubectl get ingress -n monitoring kube-prometheus-stack-prometheus
NAME CLASS HOSTS ADDRESS
PORTS AGE
kube-prometheus-stack-prometheus alb prometheus.somaz.link k8s-monitoring-74e55dbc97-980732510.ap-northeast-2.elb.amazonaws.com 80 10m
(somaz:N/A) [root@kops-ec2 ~]# kubectl describe ingress -n monitoring kube-prometheus-stack-prometheus
Name: kube-prometheus-stack-prometheus
Labels: app=kube-prometheus-stack-prometheus
app.kubernetes.io/instance=kube-prometheus-stack
app.kubernetes.io/managed-by=Helm
app.kubernetes.io/part-of=kube-prometheus-stack
app.kubernetes.io/version=45.0.0
chart=kube-prometheus-stack-45.0.0
heritage=Helm
release=kube-prometheus-stack
Namespace: monitoring
Address: k8s-monitoring-74e55dbc97-980732510.ap-northeast-2.elb.amazonaws.com
Ingress Class: alb
Default backend: <default>
Rules:
Host Path Backends
---- ---- --------
prometheus.somaz.link
/* kube-prometheus-stack-prometheus:9090 (172.30.89.62:9090)
Annotations: alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:ap-northeast-2:611841095956:certificate/75e6fb4f-5999-4701-80f2-ab94e015bc9b
alb.ingress.kubernetes.io/group.name: monitoring
alb.ingress.kubernetes.io/listen-ports: [{"HTTPS":443}, {"HTTP":80}]
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/target-type: ip
meta.helm.sh/release-name: kube-prometheus-stack
meta.helm.sh/release-namespace: monitoring
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfullyReconciled 10m ingress Successfully reconciled
# 프로메테우스 ingress 도메인으로 웹 접속
(somaz:N/A) [root@kops-ec2 ~]# echo -e "Prometheus Web URL = https://prometheus.$KOPS_CLUSTER_NAME"
Prometheus Web URL = https://prometheus.somaz.link
# 웹 상단 주요 메뉴 설명
1. 경고(Alert) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
2. 그래프(Graph) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회
3. 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인
4. 도움말(Help)
프로메테우스 설정(Configuration) 확인 : Status → Configuration ⇒ “node-exporter” 검색
global:
scrape_interval: 30s # 메트릭 가져오는(scrape) 주기
scrape_timeout: 10s # 메트릭 가져오는(scrape) 타임아웃
evaluation_interval: 30s # alert 보낼지 말지 판단하는 주기
...
- job_name: serviceMonitor/monitoring/kube-prometheus-stack-prometheus-node-exporter/0
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
...
kubernetes_sd_configs: # 서비스 디스커버리(SD) 방식을 이용하고, 파드의 엔드포인트 List 자동 반영
- role: endpoints
kubeconfig_file: ""
follow_redirects: true
enable_http2: true
namespaces:
own_namespace: false
names:
- monitoring # 서비스 엔드포인트가 속한 네임 스페이스 이름을 지정, 서비스 네임스페이스가 속한 포트 번호를 구분하여 메트릭 정보를 가져옴
전체 메트릭 대상(Targets) 확인 : Status → Targets
- 해당 스택은 ‘노드-익스포터’, cAdvisor, 쿠버네티스 전반적인 현황 이외에 다양한 메트릭을 포함
- kube-proxy 는 현재 정보를 가져오지 못하고 있습니다! → 멤버분들 한번 해결해보세요!
# 모니터링
watch kubectl get pod -n kube-system -l k8s-app=kube-proxy
# 확인 및 조치 : kube-proxy는 Static pod 스태틱 파드로 배포됨
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME sudo ss -tnlp | grep kube-proxy
LISTEN 0 32768 127.0.0.1:10249 0.0.0.0:* users:(("kube-proxy",pid=4230,fd=15))
LISTEN 0 32768 *:10256 *:* users:(("kube-proxy",pid=4230,fd=10))
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME ls /etc/kubernetes/manifests
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME cat /etc/kubernetes/manifests/kube-proxy.manifest
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME grep 127.0.0.1 /etc/kubernetes/manifests/kube-proxy.manifest
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME sudo sed -i 's/127.0.0.1/0.0.0.0/g' /etc/kubernetes/manifests/kube-proxy.manifest
- 해결 방법(스터디원 이상현님 참고)
# 모니터링
watch kubectl get pod -n kube-system -l k8s-app=kube-proxy
# 확인 및 조치 : kube-proxy는 Static pod 스태틱 파드로 배포됨
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME sudo ss -tnlp | grep kube-proxy
LISTEN 0 32768 127.0.0.1:10249 0.0.0.0:* users:(("kube-proxy",pid=4230,fd=15))
LISTEN 0 32768 *:10256 *:* users:(("kube-proxy",pid=4230,fd=10))
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME ls /etc/kubernetes/manifests
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME cat /etc/kubernetes/manifests/kube-proxy.manifest
# 마스터 노드에 SSH 접속 후 kube-proxy.manifest 수정 : kube-proxy 파드 재배포됨
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME
----------------------------
sudo sed -i -r -e "/v=2/a\ - --metrics-bind-address=0.0.0.0:10249" /etc/kubernetes/manifests/kube-proxy.manifest
sudo ss -tnlp | grep kube-proxy
exit
----------------------------
- 메트릭을 그래프(Graph)로 조회 : Graph - 아래 PromQL 쿼리(전체 클러스터 노드의 CPU 사용량 합계)입력 후 조회 → Graph 확인
1- avg(rate(node_cpu_seconds_total{mode="idle"}[1m]))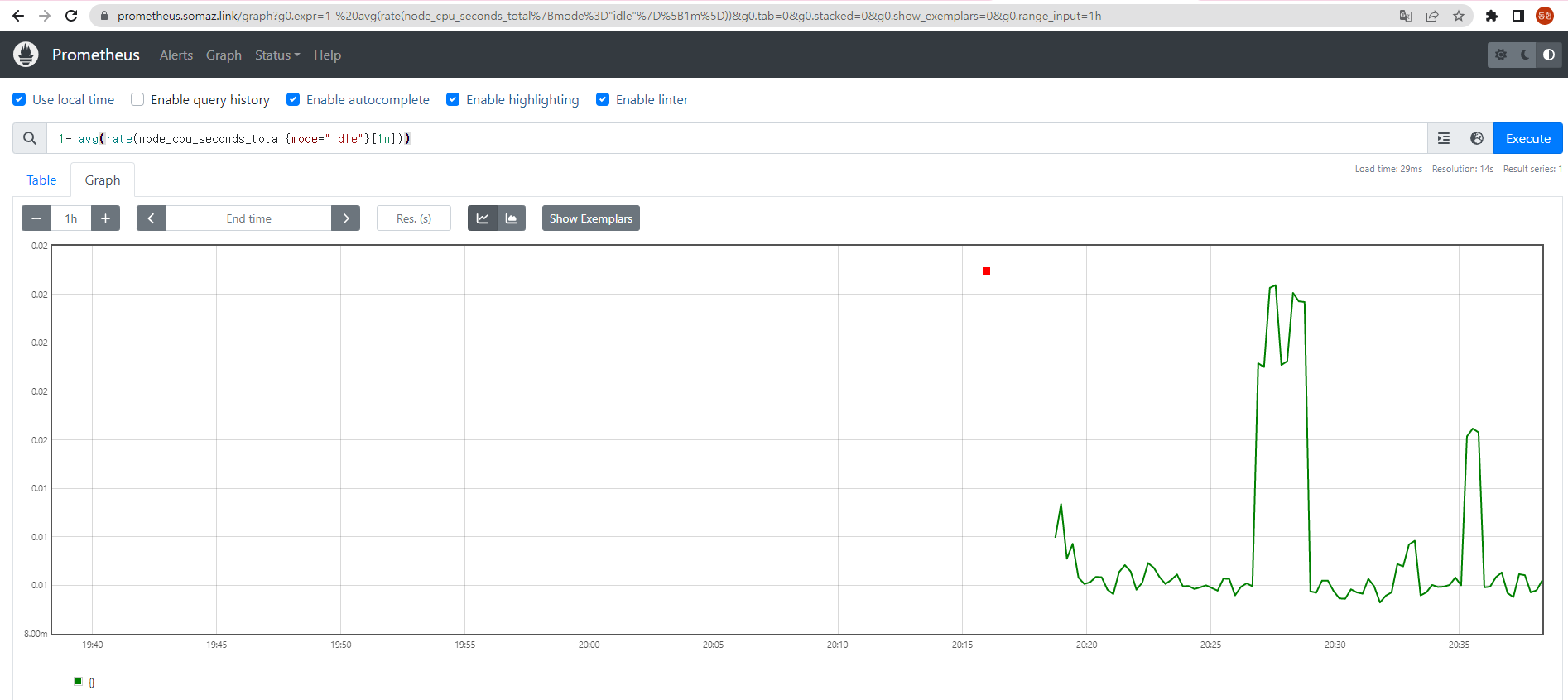
# 노드 메트릭
node 입력 후 자동 출력되는 메트릭 확인 후 선택
node_boot_time_seconds
# kube 메트릭
kube 입력 후 자동 출력되는 메트릭 확인 후 선택
그라파나 Grafana
소개 및 웹 접속
- TSDB 데이터를 시각화, 다양한 데이터 형식 지원(메트릭, 로그, 트레이스 등)
- 링크
- 그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않음
- → 현재 실습 환경에서는 데이터 소스는 프로메테우스를 사용
- 접속 정보 확인 및 로그인 : 기본 계정 - admin / prom-operator
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속
(somaz:N/A) [root@kops-ec2 ~]# echo -e "Grafana Web URL = https://grafana.$KOPS_CLUSTER_NAME"
Grafana Web URL = https://grafana.somaz.link
기본 대시보드 확인

- Search dashboards : 대시보드 검색
- Starred : 즐겨찾기 대시보드
- Dashboards : 대시보드 전체 목록 확인
- Explore : 쿼리 언어 PromQL를 이용해 메트릭 정보를 그래프 형태로 탐색
- Alerting : 경고, 에러 발생 시 사용자에게 경고를 전달
- Configuration : 설정, 예) 데이터 소스 설정 등
- Server admin : 사용자, 조직, 플러그인 등 설정
- admin : admin 사용자의 개인 설정
- Configuration → Data sources
- 스택의 경우 자동으로 프로메테우스를 데이터 소스로 추가해둠 ← 서비스 주소 확인

# 서비스 주소 확인
(somaz:N/A) [root@kops-ec2 ~]# kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-prometheus ClusterIP 100.71.254.17 <none> 9090/TCP 28m
NAME ENDPOINTS AGE
endpoints/kube-prometheus-stack-prometheus 172.30.89.62:9090 28m
해당 데이터 소스 접속 확인
# 테스트용 파드 배포
(somaz:N/A) [root@kops-ec2 ~]# kubectl apply -f ~/pkos/2/netshoot-2pods.yaml
pod/pod-1 created
pod/pod-2 created
(somaz:N/A) [root@kops-ec2 ~]# kubectl apply -f ~/pkos/2/netshoot-2pods.yaml
pod/pod-1 created
pod/pod-2 created
# 접속 확인
(somaz:N/A) [root@kops-ec2 ~]# kubectl exec -it pod-1 -- nslookup kube-prometheus-stack-prometheus.monitoring
Server: 100.64.0.10
Address: 100.64.0.10#53
Name: kube-prometheus-stack-prometheus.monitoring.svc.cluster.local
Address: 100.71.254.17
(somaz:N/A) [root@kops-ec2 ~]# kubectl exec -it pod-1 -- curl -s kube-prometheus-stack-prometheus.monitoring:9090/graph -v
* Trying 100.71.254.17:9090...
* Connected to kube-prometheus-stack-prometheus.monitoring (100.71.254.17) port 9090 (#0)
> GET /graph HTTP/1.1
> Host: kube-prometheus-stack-prometheus.monitoring:9090
> User-Agent: curl/7.87.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Date: Sun, 12 Feb 2023 11:48:13 GMT
< Content-Length: 734
< Content-Type: text/html; charset=utf-8
<
* Connection #0 to host kube-prometheus-stack-prometheus.monitoring left intact
<!doctype html><html lang="en"><head><meta charset="utf-8"/><link rel="shortcut icon" href="./favicon.ico"/><meta name="viewport" content="width=device-width,initial-scale=1,shrink-to-fit=no"/><meta name="theme-color" content="#000000"/><script>const GLOBAL_CONSOLES_LINK="",GLOBAL_AGENT_MODE="false",GLOBAL_READY="true"</script><link rel="manifest" href="./manifest.json" crossorigin="use-credentials"/><title>Prometheus Time Series Collection and Processing Server</title><script defer="defer" src="./static/js/main.c1286cb7.js"></script><link href="./static/css/main.cb2558a0.css" rel="stylesheet"></head><body class="bootstrap"><noscript>You need to enable JavaScript to run this app.</noscript><div id="root"></div></body></html>(s
대시보드 사용 : 기본 대시보드와 공식 대시보드 가져오기
기본 대시보드
- 스택을 통해서 설치된 기본 대시보드 확인 : Dashboards → Browse
- (대략) 분류 : 자원 사용량 - Cluster/POD Resources, 노드 자원 사용량 - Node Exporter, 주요 애플리케이션 - CoreDNS 등
- 확인해보자 - K8S / CR / Cluster, Node Exporter / Use Method / Cluster

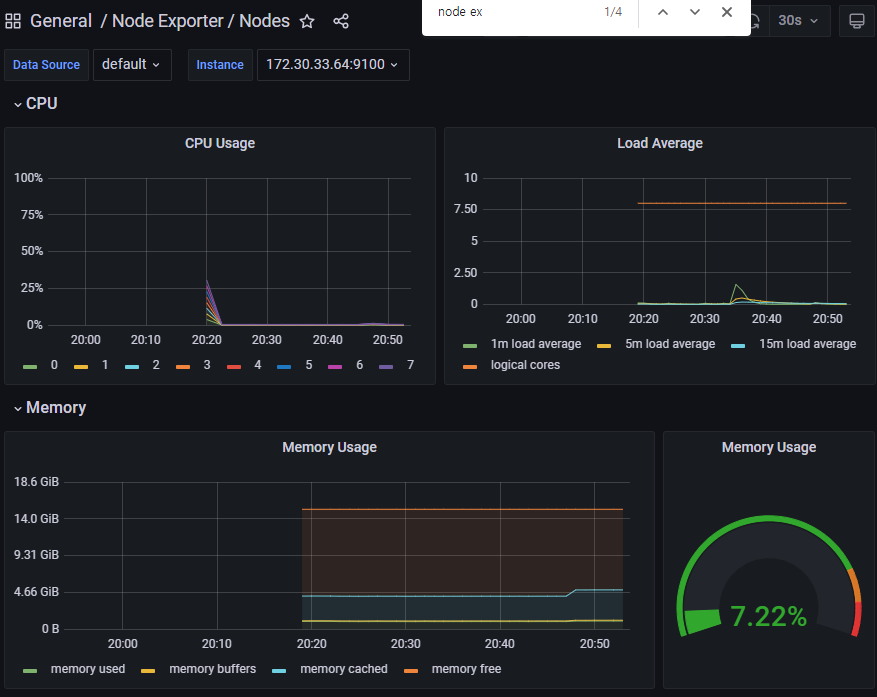

공식 대시보드 가져오기 - 링크
- kube-syate-metrics-v2 가져와보자 : Dashboard ID copied! (13332) 클릭 - 링크
- [kube-syate-metrics-v2] Dashboard → Import → 13332 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
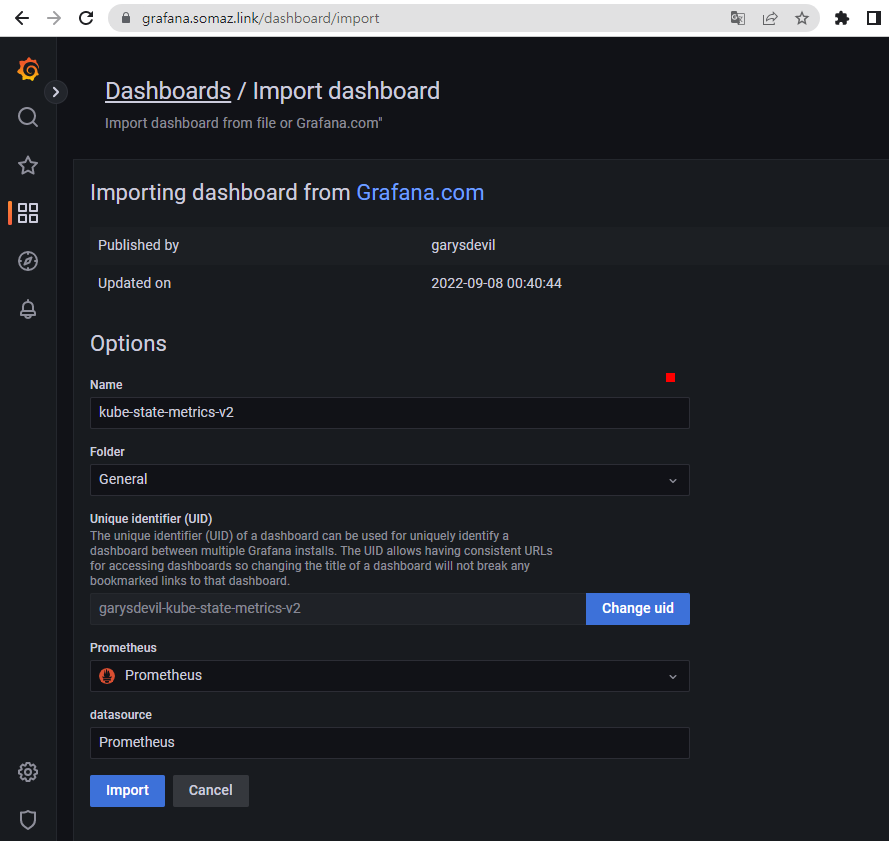
- [Node Exporter Full] Dashboard → Import → 1860 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭


NGINX 애플리케이션 모니터링 설정 및 접속
- 서비스모니터 동작

- nginx 를 helm 설치 시 프로메테우스 익스포터 Exporter 옵션 설정 시 자동으로 nginx 를 프로메테우스 모니터링에 등록 가능!
- 프로메테우스 설정에서 nginx 모니터링 관련 내용을 서비스 모니터 CRD로 추가 가능!
- 기존 애플리케이션 파드에 프로메테우스 모니터링을 추가하려면 사이드카 방식을 사용하며 exporter 컨테이너를 추가!
nginx 웹 서버 helm 설치 - Helm
- nginx webserver helm chart 사용
- 아래의 enabled : true 변경하여 사용
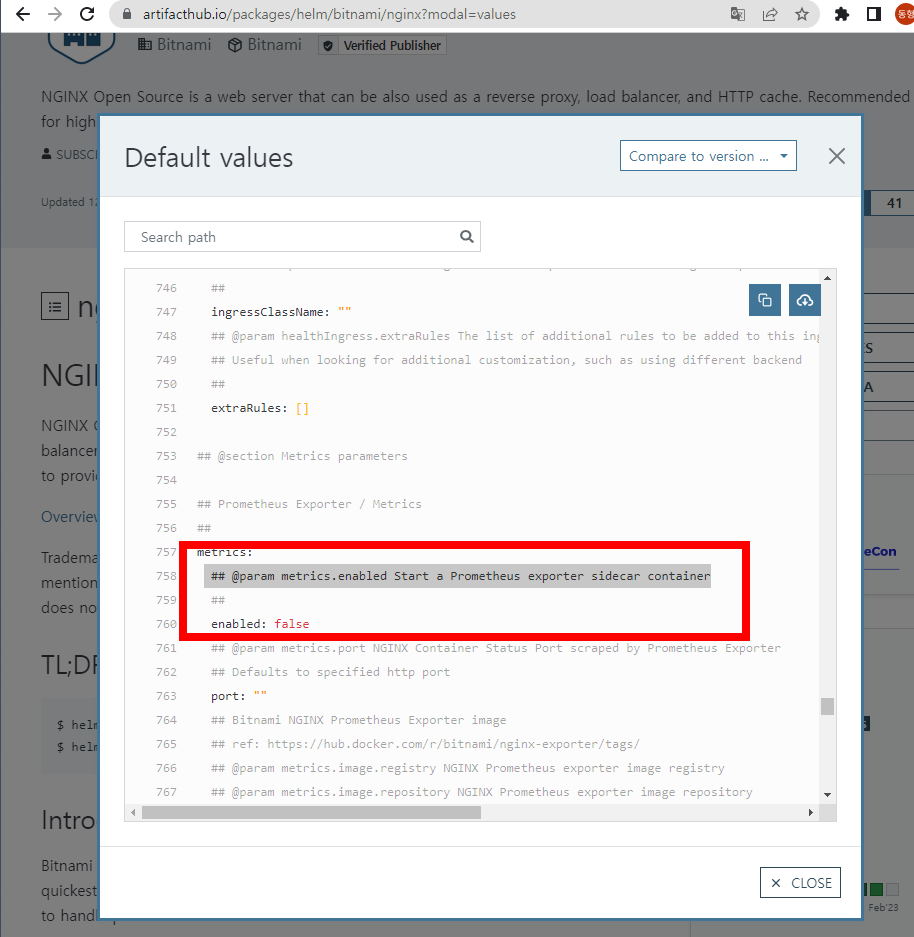
# 레포 추가
(somaz:N/A) [root@kops-ec2 ~]# helm repo add bitnami https://charts.bitnami.com/bitnami
"bitnami" has been added to your repositories
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용, nginx 노출은 CLB 기본 사용
cat <<EOT > ~/nginx-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 파일 확인
(somaz:N/A) [root@kops-ec2 ~]# cat ~/nginx-values.yaml | yh
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
# 배포
(somaz:N/A) [root@kops-ec2 ~]# helm install nginx bitnami/nginx --version 13.2.23 -f nginx-values.yaml
NAME: nginx
LAST DEPLOYED: Sun Feb 12 21:21:40 2023
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: nginx
CHART VERSION: 13.2.23
APP VERSION: 1.23.3
** Please be patient while the chart is being deployed **
NGINX can be accessed through the following DNS name from within your cluster:
nginx.default.svc.cluster.local (port 80)
To access NGINX from outside the cluster, follow the steps below:
1. Get the NGINX URL by running these commands:
NOTE: It may take a few minutes for the LoadBalancer IP to be available.
Watch the status with: 'kubectl get svc --namespace default -w nginx'
export SERVICE_PORT=$(kubectl get --namespace default -o jsonpath="{.spec.ports[0].port}" services nginx)
export SERVICE_IP=$(kubectl get svc --namespace default nginx -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
echo "http://${SERVICE_IP}:${SERVICE_PORT}"
# CLB에 ExternanDNS 로 도메인 연결
(somaz:N/A) [root@kops-ec2 ~]# kubectl annotate service nginx "external-dns.alpha.kubernetes.io/hostname=nginx.$KOPS_CLUSTER_NAME"
service/nginx annotated
# 확인
(somaz:N/A) [root@kops-ec2 ~]# kubectl get pod,svc,ep
NAME READY STATUS RESTARTS AGE
pod/nginx-697fd655bf-qqbhg 2/2 Running 0 4m17s
pod/pod-1 1/1 Running 0 39m
pod/pod-2 1/1 Running 0 39m
NAME TYPE CLUSTER-IP EXTERNAL-IP
PORT(S) AGE
service/kubernetes ClusterIP 100.64.0.1 <none>
443/TCP 94m
service/nginx LoadBalancer 100.69.218.103 a2bbb9186680e47c5983216a4dd11c8f-1766528951.ap-northeast-2.elb.amazonaws.com 80:31001/TCP,9113:30289/TCP 4m17s
NAME ENDPOINTS AGE
endpoints/kubernetes 172.30.61.109:443 94m
endpoints/nginx 172.30.69.172:9113,172.30.69.172:8080 4m17s
(somaz:N/A) [root@kops-ec2 ~]# kubectl get servicemonitor -n monitoring nginx
NAME AGE
nginx 87s
kubectl get servicemonitor -n monitoring nginx -o json | jq
# nginx 파드내에 컨테이너 갯수 확인
(somaz:N/A) [root@kops-ec2 ~]# kubectl get pod -l app.kubernetes.io/instance=nginx
NAME READY STATUS RESTARTS AGE
nginx-697fd655bf-qqbhg 2/2 Running 0 2m3s
(somaz:N/A) [root@kops-ec2 ~]# kubectl describe pod -l app.kubernetes.io/instance=nginx
Name: nginx-697fd655bf-qqbhg
Namespace: default
Priority: 0
Service Account: default
Node: i-0949cd7beadbc375c/172.30.72.213
Start Time: Sun, 12 Feb 2023 21:21:40 +0900
Labels: app.kubernetes.io/instance=nginx
app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=nginx
helm.sh/chart=nginx-13.2.23
pod-template-hash=697fd655bf
Annotations: kubernetes.io/limit-ranger: LimitRanger plugin set: cpu request for container nginx; cpu request for container metrics
Status: Running
IP: 172.30.69.172
IPs:
IP: 172.30.69.172
Controlled By: ReplicaSet/nginx-697fd655bf
Containers:
nginx:
Container ID: containerd://b9a76b40dfe943a9f41103c407dcacbda0b5d04f43ccc987c1d74e1aba668925
Image: docker.io/bitnami/nginx:1.23.3-debian-11-r17
Image ID: docker.io/bitnami/nginx@sha256:a59c09a20b23165c099084cf603aec60924f3e91ab24f1e8969714c32344bfa3
Port: 8080/TCP
Host Port: 0/TCP
State: Running
Started: Sun, 12 Feb 2023 21:21:45 +0900
Ready: True
Restart Count: 0
Requests:
cpu: 100m
Liveness: tcp-socket :http delay=30s timeout=5s period=10s #success=1 #failure=6
Readiness: tcp-socket :http delay=5s timeout=3s period=5s #success=1 #failure=3
Environment:
BITNAMI_DEBUG: false
NGINX_HTTP_PORT_NUMBER: 8080
Mounts: <none>
metrics:
Container ID: containerd://81cc8a5d5079018674c16b082e512621004f17a2ed35a18256a9f30b8d32cab3
Image: docker.io/bitnami/nginx-exporter:0.11.0-debian-11-r44
Image ID: docker.io/bitnami/nginx-exporter@sha256:91c7e1a893011a15a5ee450c8ea3e8d21c2337f6e00ec43b7f8f1740af2ea25f
Port: 9113/TCP
Host Port: 0/TCP
Command:
/usr/bin/exporter
-nginx.scrape-uri
http://127.0.0.1:8080/status
State: Running
Started: Sun, 12 Feb 2023 21:21:49 +0900
Ready: True
Restart Count: 0
Requests:
cpu: 100m
Liveness: http-get http://:metrics/metrics delay=15s timeout=5s period=10s #success=1 #failure=3
Readiness: http-get http://:metrics/metrics delay=5s timeout=1s period=10s #success=1 #failure=3
Environment: <none>
Mounts: <none>
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes: <none>
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m17s default-scheduler Successfully assigned default/nginx-697fd655bf-qqbhg to i-0949cd7beadbc375c
Normal Pulling 2m18s kubelet Pulling image "docker.io/bitnami/nginx:1.23.3-debian-11-r17"
Normal Pulled 2m13s kubelet Successfully pulled image "docker.io/bitnami/nginx:1.23.3-debian-11-r17" in 4.65643916s
Normal Created 2m13s kubelet Created container nginx
Normal Started 2m13s kubelet Started container nginx
Normal Pulling 2m13s kubelet Pulling image "docker.io/bitnami/nginx-exporter:0.11.0-debian-11-r44"
Normal Pulled 2m10s kubelet Successfully pulled image "docker.io/bitnami/nginx-exporter:0.11.0-debian-11-r44" in 3.676932752s
Normal Created 2m9s kubelet Created container metrics
Normal Started 2m9s kubelet Started container metrics
# 접속 주소 확인 및 접속
(somaz:N/A) [root@kops-ec2 ~]# echo -e "Nginx WebServer URL = http://nginx.$KOPS_CLUSTER_NAME"
Nginx WebServer URL = http://nginx.somaz.link
(somaz:N/A) [root@kops-ec2 ~]# curl -s http://nginx.$KOPS_CLUSTER_NAME
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
(somaz:N/A) [root@kops-ec2 ~]# kubectl logs deploy/nginx -f
Defaulted container "nginx" out of: nginx, metrics
nginx 12:21:45.31
nginx 12:21:45.31 Welcome to the Bitnami nginx container
nginx 12:21:45.31 Subscribe to project updates by watching https://github.com/bitnami/containers
nginx 12:21:45.31 Submit issues and feature requests at https://github.com/bitnami/containers/issues
nginx 12:21:45.31
nginx 12:21:45.31 INFO ==> ** Starting NGINX setup **
nginx 12:21:45.32 INFO ==> Validating settings in NGINX_* env vars
nginx 12:21:45.33 INFO ==> No custom scripts in /docker-entrypoint-initdb.d
nginx 12:21:45.33 INFO ==> Initializing NGINX
realpath: /bitnami/nginx/conf/vhosts: No such file or directory
nginx 12:21:45.35 INFO ==> ** NGINX setup finished! **
nginx 12:21:45.35 INFO ==> ** Starting NGINX **
172.30.33.64 - - [12/Feb/2023:12:26:23 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.79.1" "-"
172.30.72.213 - - [12/Feb/2023:12:26:48 +0000] "GET / HTTP/1.1" 200 409 "-" "python-requests/2.28.2" "-"
172.30.33.64 - - [12/Feb/2023:12:26:53 +0000] "GET / HTTP/1.1" 200 409 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36" "-"
2023/02/12 12:26:53 [error] 45#45: *103 open() "/opt/bitnami/nginx/html/favicon.ico" failed (2: No such file or directory), client: 172.30.33.64, server: , request: "GET /favicon.ico HTTP/1.1", host: "nginx.somaz.link", referrer: "http://nginx.somaz.link/"
172.30.33.64 - - [12/Feb/2023:12:26:53 +0000] "GET /favicon.ico HTTP/1.1" 404 180 "http://nginx.somaz.link/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36" "-"
# 반복 접속
while true; do curl -s http://nginx.$KOPS_CLUSTER_NAME -I | head -n 1; date; sleep 1; done
서비스 모니터링 생성 후 1분 정도 후에 프로메테우스 웹서버
- State → Targets 에 nginx 서비스 모니터 추가 확인
NGINX 애플리케이션 모니터링 대시보드 추가
- 그라파나에 12708 대시보드 추가


(실습 완료 후) 자원 삭제
헬름 차트 삭제
# nginx 삭제
helm uninstall nginx
# 프로메테우스 스택 삭제
helm uninstall -n monitoring kube-prometheus-stack
kOps 클러스터 삭제 & AWS CloudFormation 스택 삭제
kops delete cluster --yes && aws cloudformation delete-stack --stack-name mykops
스터디 5주차 후기
이번 5주차에는 Prometheus와 Grafana에 대해 본격적으로 다뤄보았다.
이 두 가지 도구는 예전부터 사내에서 사용하고 있었지만, 직접 운영하거나 설정할 기회는 없었기에 막연히 어렵고 낯설게만 느껴졌던 도구들이었다.
그러나 이번 스터디를 통해 Helm으로 Prometheus Stack을 설치하고, 다양한 대시보드를 Grafana에 임포트해보면서
이 도구들이 정말 강력한 모니터링 및 시각화 솔루션이라는 것을 체감할 수 있었다.
특히, Helm 차트 하나만으로 구성요소 전체를 빠르게 설치하고, ALB Ingress + ACM으로 웹 접속을 간편히 구성하는 부분은 실무에서도 활용도가 높아 보였다.
Exporters와 ServiceMonitor를 통한 모니터링 연동 방식도 익힐 수 있어 유익한 시간이었다.
이번 기회에 사내 시스템에 적용된 Grafana 대시보드를 들여다보면서, 실제 우리가 수집하고 있는 메트릭들이 어떤 의미를 가지는지 더 깊이 파악해봐야겠다는 생각이 들었다.
6주차도 힘차게! 함께 화이팅
'교육, 커뮤니티 후기 > PKOS 쿠버네티스 스터디' 카테고리의 다른 글
| PKOS 쿠버네티스 스터디 7주차 - K8S 보안 (0) | 2023.02.28 |
|---|---|
| PKOS 쿠버네티스 스터디 6주차 - 얼럿매니저 로깅시스템 (0) | 2023.02.19 |
| PKOS 쿠버네티스 스터디 4주차 - Harbor Gitlab Argocd (2) | 2023.02.06 |
| PKOS 쿠버네티스 스터디 3주차 - Ingress & Storage (4) | 2023.02.03 |
| PKOS 쿠버네티스 스터디 2주차 - 쿠버네티스 네트워크 (0) | 2023.01.16 |