
Overview
Kubernetes에서 일반적인 Service는 클러스터 내의 파드들 사이에 로드 밸런싱과 가상 IP(ClusterIP)를 제공하는 방식으로 작동한다. 하지만, 데이터베이스나 Stateful 애플리케이션처럼 각 파드에 직접적인 네트워크 접근이 필요한 경우에는 이 방식이 적합하지 않다.
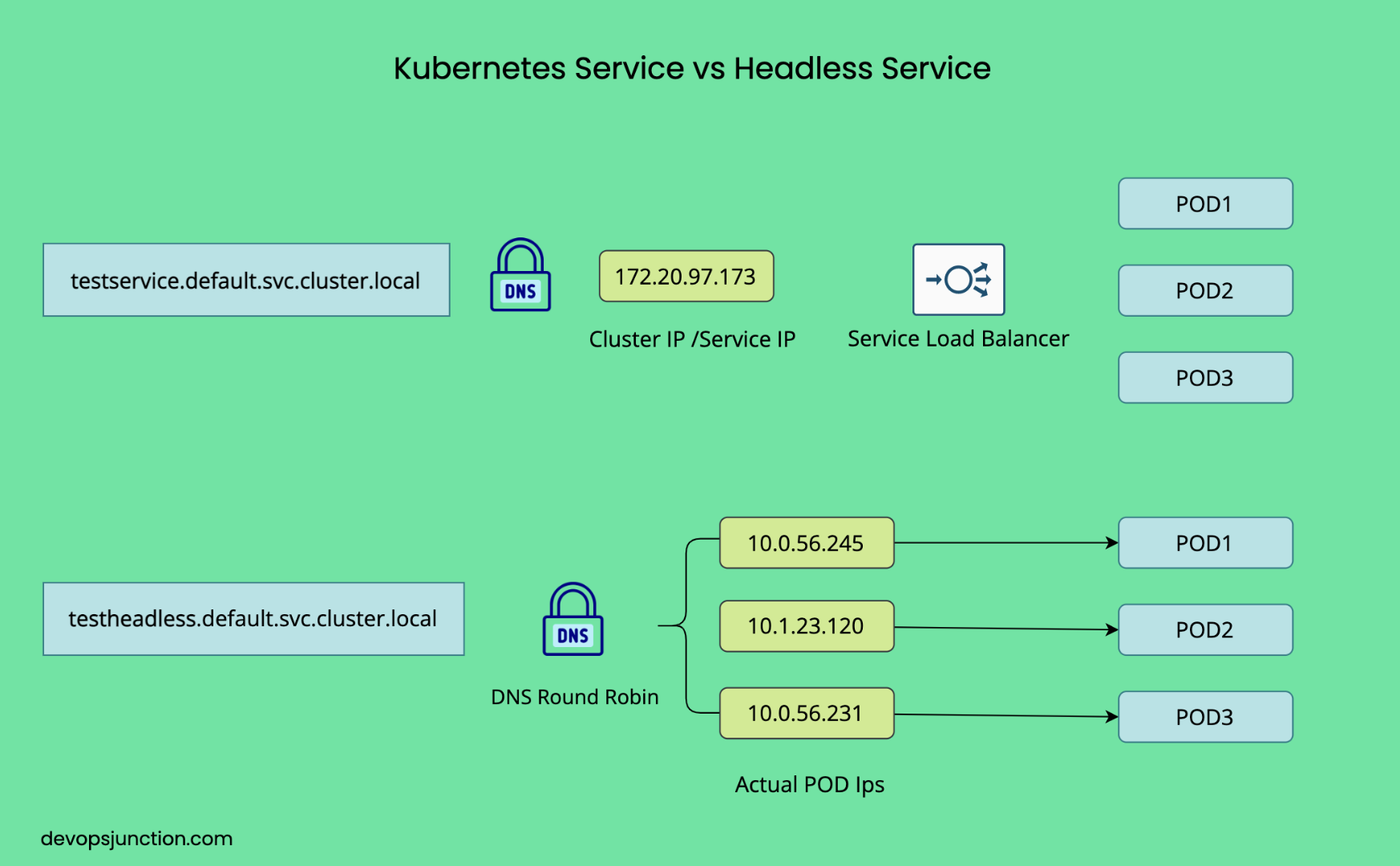
이런 상황에서 사용하는 것이 바로 Headless Service이다. `Headless Service는 clusterIP: None` 으로 설정되어 있으며, DNS를 통해 각 파드의 개별 IP를 직접 노출시켜준다.
이로 인해 클라이언트는 파드 하나하나에 직접 접근할 수 있게 되고, 이는 클러스터링 기반 DB 시스템(Cassandra, MongoDB 등)이나 StatefulSet 환경에서 매우 유용하게 활용된다.
📅 관련 글
2024.02.02 - [Container Orchestration/Kubernetes] - Kubernetes Network
Kubernetes Headless Service란?
Kubernetes Headless Service는 로드 밸런싱이나 할당된 클러스터 IP 주소를 제공하지 않는 특별한 유형의 서비스이다. 대신, DNS 이름으로 개별 파드에 직접 액세스할 수 있으며, 이는 데이터베이스나 StatefulSet 과 같이 파드와의 직접 통신이 필요한 애플리케이션에 특히 유용하다.
Headless Service의 주요 특징
No Cluster IP
- Headless Service는 `spec.clusterIP` 를 `None` 으로 설정하여 생성된다. 이는 Kubernetes가 서비스에 가상 IP를 할당하지 않음을 의미한다.
DNS Records for Pods
- 로드 밸런서를 통해 트래픽을 라우팅하는 대신 Kubernetes는 각 파드에 대해 개별 DNS 레코드를 생성한다. 이러한 DNS 레코드를 사용하면 클라이언트가 특정 파드에 직접 연결할 수 있다.
Direct Pod Communication
- 애플리케이션 또는 서비스는 로드 밸런싱을 제공하는 일반적인 서비스 추상화를 우회하여 파드와 직접 통신할 수 있다.
일반적인 사용 사례
- Headless Service는 일반적으로 StatefulSets와 함께 사용된다. 여기서 각 포드에는 고유한 ID가 필요하고 개별적으로 주소를 지정할 수 있어야 한다.
- 클러스터링을 위해 개별 포드에 직접 액세스해야 하는 데이터베이스(예: Cassandra, Kafka, MongoDB)와 같은 특정 유형의 애플리케이션에도 사용된다.
Headless Service의 이점
세분화된 파드 액세스
- 노드별 작업이나 상태가 필요한 애플리케이션에는 파드에 대한 직접 액세스가 필수적이다.
단순화된 DNS 관리
- Kubernetes는 Headless Service의 각 파드에 대해 DNS 레코드를 자동으로 관리한다.
상태 저장 애플리케이션 지원
- 지속적인 ID와 연결이 중요한 StatefulSet 및 분산 데이터베이스에 유용하다.
Headless Service 작동 방식
Headless Service를 생성하면 Kubernetes는 DNS 레코드를 다르게 생성한다.
- 일반적인 서비스의 경우 단일 DNS 항목은 서비스의 클러스터 IP를 가리킨다.
- Headless Service의 경우 각 파드에 대해 DNS 항목이 생성된다. 예를 들어, `default` 네임스페이스에 3개의 파드가 있는 `my-service` 라는 이름의 Headless Service가 있는 경우 DNS 레코드는 다음과 같이 표시 된다.
my-service.default.svc.cluster.local -> No IP (headless service)
pod-0.my-service.default.svc.cluster.local -> Pod-0 IP
pod-1.my-service.default.svc.cluster.local -> Pod-1 IP
pod-2.my-service.default.svc.cluster.local -> Pod-2 IP
EndpointSlice와의 관계
- Kubernetes는 Headless Service의 Endpoints를 관리할 때 EndpointSlice를 사용한다.
- 클러스터 내 파드가 많을 경우 이 Slice 기반 구조가 성능에 영향을 미칠 수 있으며, 디버깅 시 `kubectl get endpointslice` 명령어도 유용하다.
Headless Service 만들기
Headless Service에 대한 YAML 구성의 예는 다음과 같다.
apiVersion: v1
kind: Service
metadata:
name: headless-service
spec:
clusterIP: None
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
StatefulSet과 통합
StatefulSet는 Headless Service를 사용하여 파드 네트워크 ID를 관리하는 경우가 많다. 각 파드는 고유한 네트워크 ID를 가지며 개별적으로 주소를 지정할 수 있다.
- 예를들어 웹이라는 이름의 StatefulSet과 Headless Service라는 이름의 웹은 다음과 같은 DNS 이름의 파드를 생성한다.
web-0.web.default.svc.cluster.local
web-1.web.default.svc.cluster.local
Headless Service + StatefulSet 실전 예시
- 예: Cassandra, Kafka, RabbitMQ 같은 DB 클러스터 구성
- StatefulSet을 사용하면 각 파드가 정적인 DNS 주소를 갖게 되며, 클러스터의 노드로 인식 가능
cassandra-0.cassandra.default.svc.cluster.local
cassandra-1.cassandra.default.svc.cluster.local
Headless Service DNS 쿼리 동작
A/AAAA DNS 쿼리(기본값)
- Headless Service의 대한 DNS 이름 `my-service.default.svc.cluster.local` 을 쿼리하면 Kubernetes는 일치하는 모든 Pod (Endpoint)의 IP 주소를 반환한다. 즉, DNS 응답에는 여러 IP 주소(서비스를 지원하는 각 Pod에 대해 하나씩)가 포함된다.
$ nslookup my-service.default.svc.cluster.local
Name: my-service.default.svc.cluster.local
Address: 10.1.2.3
Address: 10.1.2.4
Address: 10.1.2.5
- 배포 동작 : 애플리케이션이 `my-service.default.svc.cluster.local` 에 연결되는 경우 요청의 배포는 클라이언트가 여러 IP를 처리하는 방식에 따라 달라진다. 많은 클라이언트가 무작위로 또는 라운드 로빈 방식으로 하나의 IP를 선택한다.
SRV 레코드
- 쿠버네티스는 또한 Headless Services에 대한 SRV DNS 레코드를 생성하는데 , 여기에는 개별 Pod의 DNS 이름과 포트가 포함된다. 이러한 레코드는 애플리케이션이 서비스 검색을 위해 SRV 레코드를 활용할 수 있는 경우에 유용하다.
$ dig SRV my-service.default.svc.cluster.local
;; ANSWER SECTION:
my-service.default.svc.cluster.local. 30 IN SRV 0 50 8080 pod-0.my-service.default.svc.cluster.local.
my-service.default.svc.cluster.local. 30 IN SRV 0 50 8080 pod-1.my-service.default.svc.cluster.local.
my-service.default.svc.cluster.local. 30 IN SRV 0 50 8080 pod-2.my-service.default.svc.cluster.local.
Will Requests Be Distributed?
`my-service.default.svc.cluster.local` 에 대한 요청은 Headless Service에서 Kubernetes에 의해 본질적으로 로드 밸런싱되지 않는다.
- 대신 DNS resolution 은 여러 IP(Pod당 하나)를 제공하며, 클라이언트는 사용할 IP를 결정한다.
- DNS 인식 클라이언트는 다음을 수행할 수 있다.
- 무작위로 하나의 IP를 선택한다.
- 목록의 첫 번째 IP를 한다.
- 모든 IP를 라운드 로빈 방식으로 사용한다.
- 배포에 영향을 줄 수 있는 특정 기간 동안 DNS 결과를 캐시한다.
- 클라이언트가 직접 로드 밸런싱을 구현하지 않으면 트래픽이 균등하게 분산되지 않을 수 있다.
Headless Service의 DNS TTL (Time-To-Live) 고려
- Kubernetes의 DNS는 기본적으로 레코드의 TTL(Time to Live)을 짧게 유지한다.
- 하지만 클라이언트 쪽에서 DNS 응답을 캐싱하는 경우, 특정 파드에 트래픽이 쏠릴 수 있으므로 external-dns 설정이나 클라이언트의 DNS 캐싱 전략도 고려해야 한다.
ClusterIP 서비스와의 주요 차이점
일반 ClusterIP 서비스의 경우
- 쿠버네티스는 단일 클러스터 IP를 할당하고, 모든 요청은 자동으로 Pod 전체에 걸쳐 로드 밸런싱된다.
- 클라이언트는 여러 개의 IP를 처리할 필요가 없다.
Headless Service의 경우
- 클러스터 IP가 없고 로드 밸런싱 기능도 내장되어 있지 않다.
- 클라이언트는 여러 개의 Pod IP를 직접 처리해야 한다.
결론
`my-service.default.svc.cluster.local` 에 액세스하면 트래픽이 Kubernetes에 의해 자동으로 분산되지 않는다.
- DNS는 Pod IP 목록을 확인한다.
- 클라이언트는 해당 목록을 처리하는 방법(예: 무작위 선택, 라운드 로빈)을 결정한다.
여러 Pod 간에 자동으로 로드 밸런싱을 수행해야 하는 경우 Headless Service 대신 ClusterIP 서비스를 사용해야 한다.
Headless Service를 사용하지 말아야 할 경우
- 로드 밸런싱이 필요한 경우 일반 ClusterIP, NodePort 또는 LoadBalancer 서비스를 대신 사용하면 된다.
- 개별 Pod에 직접 액세스할 필요가 없는 애플리케이션의 경우 표준 서비스로 충분하다.
Headless Service는 Kubernetes의 DNS 기능을 활용하여 파드 개별 접근을 가능하게 하는 매우 유용한 서비스 유형이다. 하지만 모든 상황에서 적합한 것은 아니며, 로드 밸런싱이 자동으로 이루어지지 않는다는 점을 반드시 이해하고 사용해야 한다.
따라서 다음과 같은 선택이 중요하다.
- 개별 파드에 직접 연결하고자 한다면 → Headless Service
- 자동 로드 밸런싱이 필요하다면 → 일반 Service (ClusterIP, LoadBalancer 등)
상태를 유지하는 앱(StatefulSet)이나 파드 간의 정해진 통신 경로가 필요한 애플리케이션에서는 Headless Service를 적극적으로 고려하되, 클라이언트 쪽의 DNS 처리 방식이나 캐싱 전략도 함께 고려해야 한다.
Reference
https://kubernetes.io/docs/concepts/services-networking/service/#headless-services
https://www.middlewareinventory.com/blog/kubernetes-headless-service/
https://loft.sh/blog/headless-vs-clusterip-service-kubernetes/
'Container Orchestration > Kubernetes' 카테고리의 다른 글
| Kubernetes Operator(CRD, CR) 생성(With kubebuilder) (0) | 2024.12.17 |
|---|---|
| Kubernetes Operator 및 Custom Resource Definitions(CRDs) 이해하기 (0) | 2024.12.12 |
| Kubernetes Deployment Strategy (0) | 2024.11.26 |
| Helm Chart Template 문법 (0) | 2024.11.15 |
| Kubernetes Garbage Collection (0) | 2024.08.30 |